推荐参阅列表
- 推荐阅读-paxos生活化案例讲解
- 推荐阅读-架构师需要了解的Paxos原理、历程及实战
- 推荐阅读-图解分布式一致性协议Paxos
- 推荐阅读-Paxos协议超级详细解释+简单实例
解决了什么
解决分布式环境下数据一致性的问题。分布式环境下不同数据副本节点之间可能数据不一致,paxos和raft算法提供了一种可靠的解决方案。
两者选主总结:
Paxos 过程并非“一轮定主”,而是:
- Paxos 共识本质是“多轮投票+承诺”模型,不一定一轮就有结果;
- Proposer 发起 Prepare(提案),Acceptor 可能因已有更大编号或其他原因不同意;
- 如果遭遇冲突,“这一轮选主/共识未成功”,需要再来一轮(提案号加大再试);
- 反复碰撞、重试,最终才有一轮被大多数同意(无其他高号重复抢票时)才定主;
- Paxos中相同Term中即使并发进入Accept阶段,但是节点已经承诺过不支持编号小的,当Accept中携带的编号为1<2时,将不被接受,无法通过选举确认阶段,所以不会出现相同Term下两个节点竞选成功
换句话说,Paxos 往往需要多轮反复,直到最终有一轮“幸运获胜”。
Raft 选主过程实际是一轮确定:
- Raft 的 Leader 选举,就是某个 Candidate 在一个任期 term 内向大家请求投票;
- 只要某个节点先获得了半数以上选票,它就立刻成为新 Leader(这一轮选举就结束);
- 若有多个节点同时竞争(即 term 中无人得半数),下一轮 term 自动开始(随机超时机制保证极少碰撞);
所以,几乎一轮选举就能选出 Leader,且选出马上进入工作阶段。
在实际应用中,Raft算法和Paxos算法也各有优劣。Raft算法相对来说更加适用于需要频繁变更集群配置的场景,例如分布式数据库的自动扩展。而Paxos算法则更适合于需要高度可用性和容错性的场景,例如分布式锁、分布式事务等,就某个值达成一致的算法。
Paxos算法任意一个节点都可接受请求,而Raft节点通过leader节点进服务。
Paxos算法
涉及到角色
- Proposer:N个,提议发起者,将提案<proposal number, n>对外公布,发送自己的提议;
- Acceptor:N个,提议接受者(一般也是投票者Proposer),Proposer提出的提议必须获得超过半数(N/2+1)的 Acceptor批准后才能通过。
- Learner:1个,提议学习者,当一个提议通过后,Learner将通过的确定性取值同步给其他未确定的Acceptor。
协议过程简单总结
一句话总结:proposer将发起提案(value)给所有accpetor,超过半数accpetor获得批准后,proposer将提案写入accpetor内,最终所有accpetor获得一致性的确定性取值,且后续不允许再修改。
若不能收集到半数投票,这一轮参与者将一直等待;
在节点角色中存在一个本地定时器,一个倒计时即为一个周期。对于选主Leader场景,如果周期内Leader未发送心跳消息,则Follower自动开启新一轮选主操作。
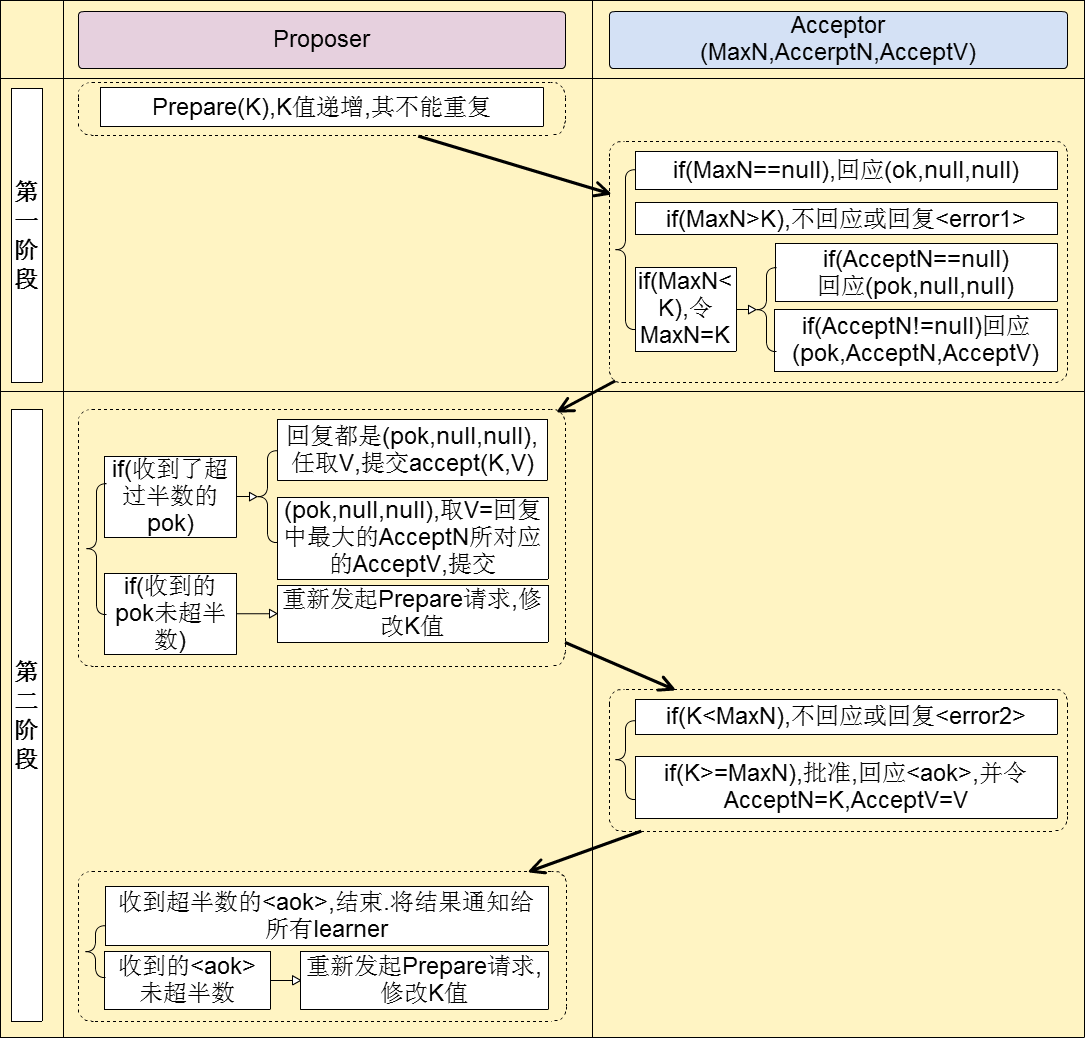
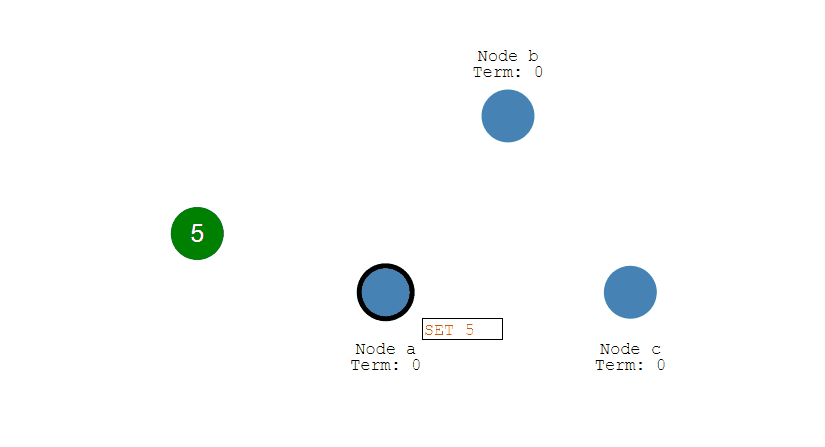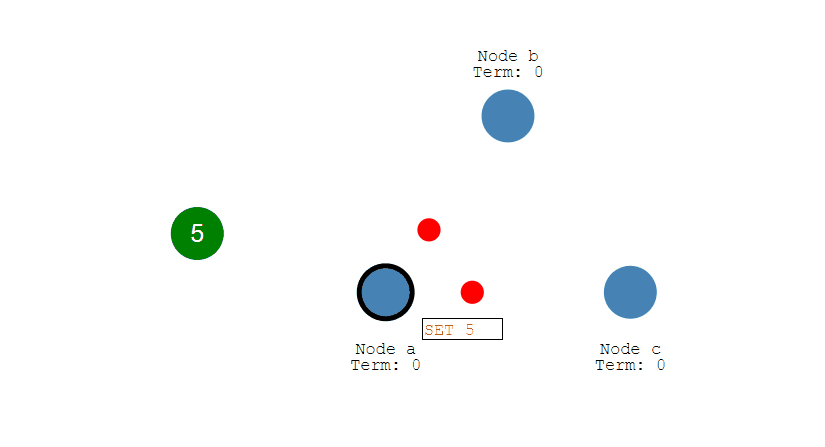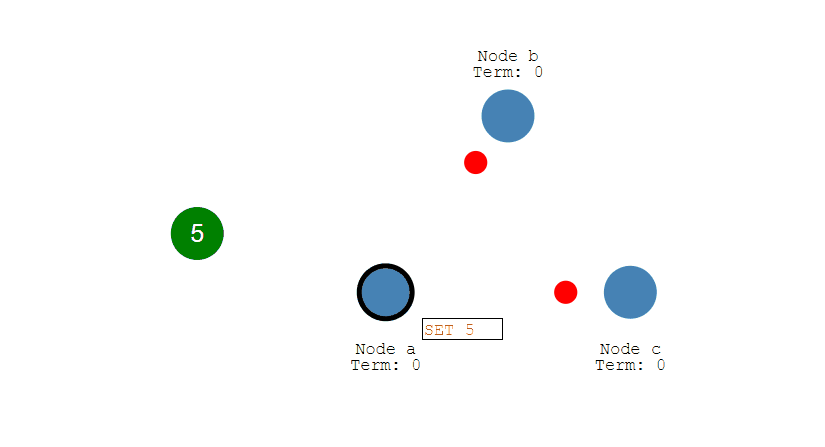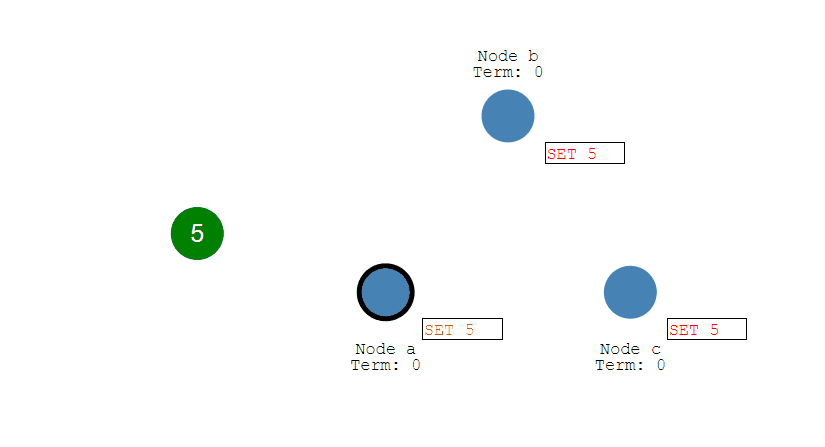
先给个示例讲解方便理解
设有 A、B、C、D、E 五位评委。
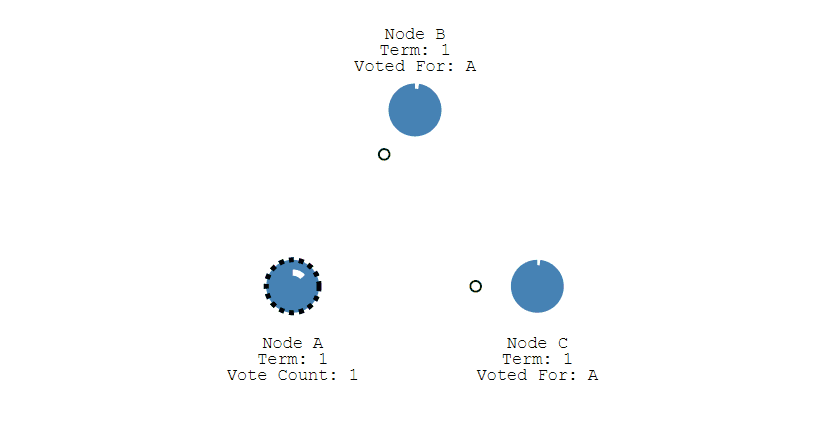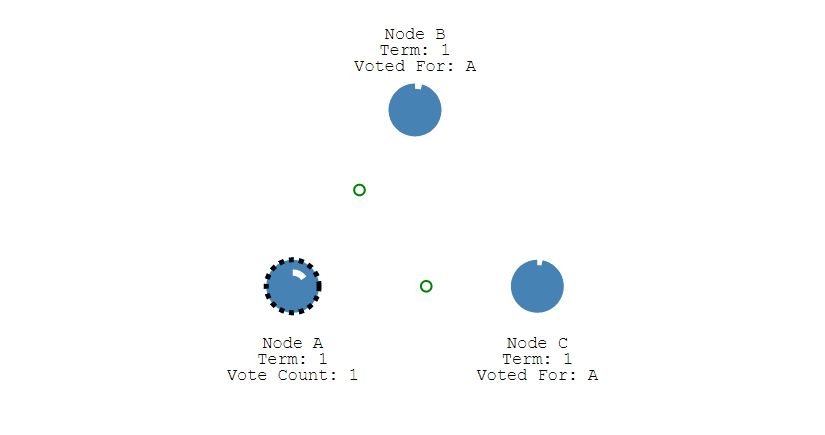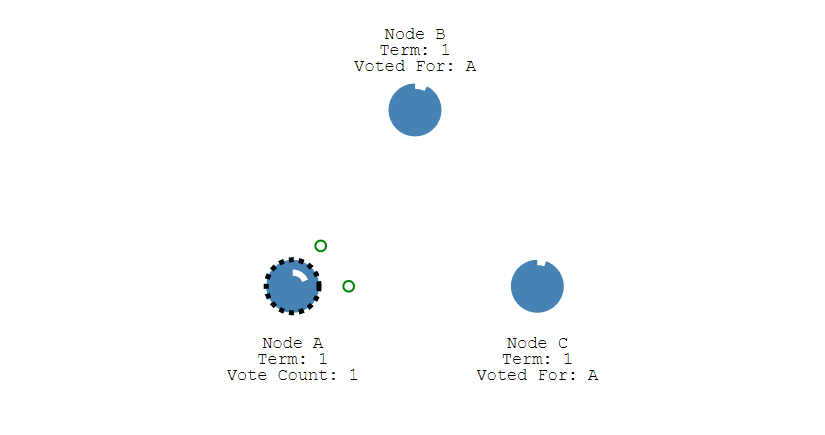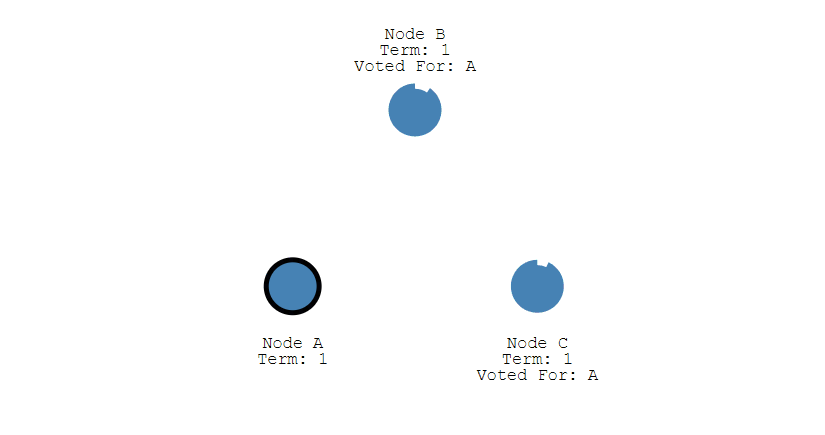
第一步:小明 Prepare(1)
- 小明编号1,向所有人说:“你们能承诺不支持更小编号吗?”
- 假设A、B还没收到,C、D、E收到,答应“好,以后 <1 的都不支持了”。
第二步:小红 Prepare(2)
- 小红编号2,向所有人说同样的问题。
- A、B此时没承诺过其他人,所以答应。
- C、D、E虽然刚答应过小明,但现在编号2 >1,仍然答应!(因为 Paxos 要求承诺总支持最高编号)。
- 整个集体都会同意支持小红。
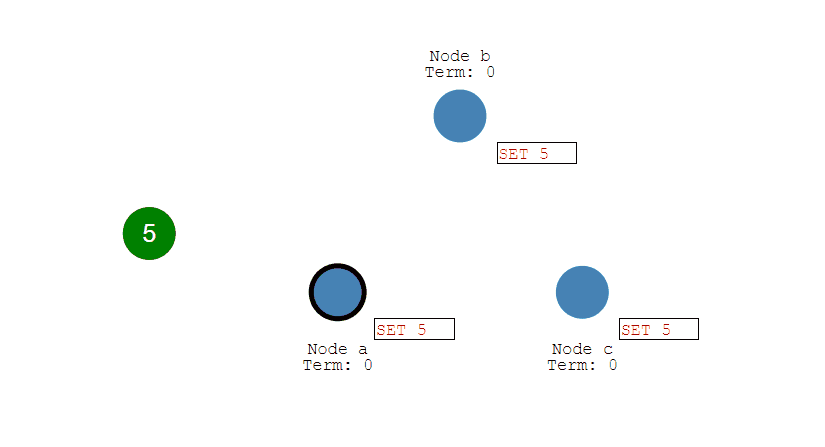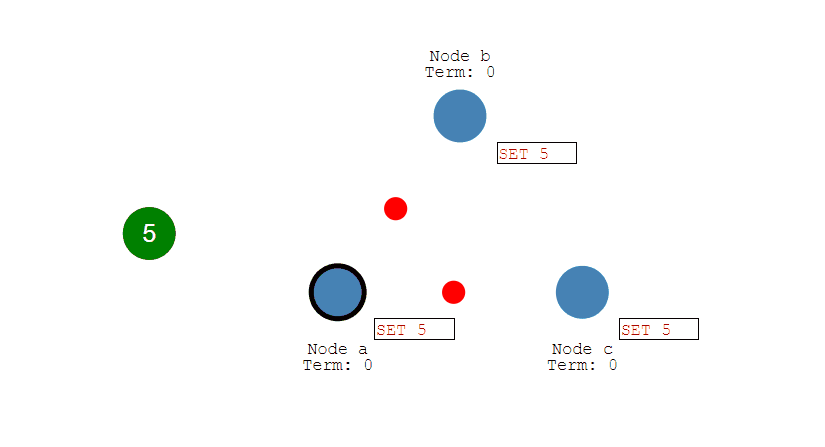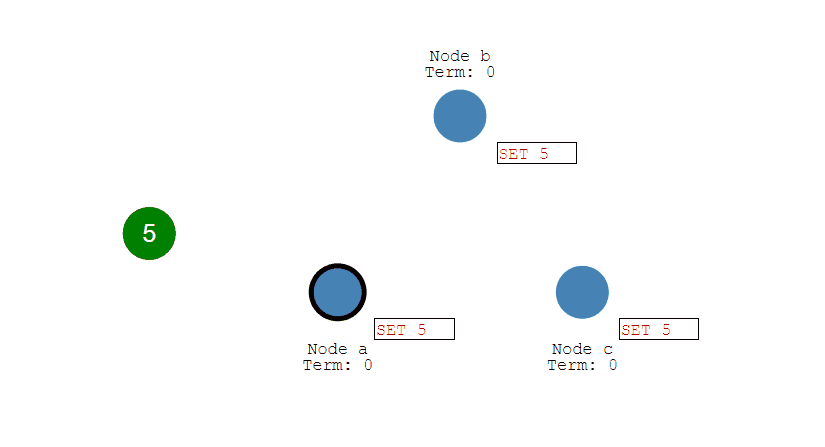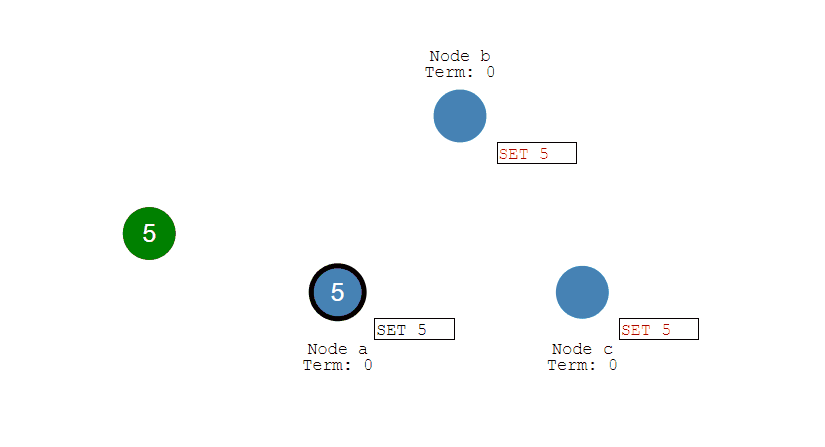
第三步:小红 Accept(2, value)
- 小红请求:“你们能接受我当班长吗?”
- 如果 C、D、E 在此之前未接受过别的更高编号提案,就答应。
- 至此,假如小红的 Accept 被大多数接受,即最终小红被选定为共识结果。
小明这时怎么办?
- 小明继续尝试 Accept(1, value) 时,A、B都没答应过编号1,可能会答应;但 C、D、E 已经承诺了编号2,不会再接受编号1 的请求。
- 所以小明 Accept(1, value) 阶段,也无法再凑够半数被拒绝掉。
不同Term下异常处理
Raft 在集群日志不一致时的 Leader 选举原理,Raft中承诺一个Term中一旦投票给某个节点后,将不在投票给其他节点,当不同Term节点都认为自己是Leader时,只要有一个 Leader 能及时用心跳/日志同步占据大多数,其他节点会识别到 term/Leader 冲突,回退成 Follower,只认更大 term/最新 Leader(即使较低的被承认过也会被替换)。
协议两大阶段
第一阶段 Prepare
P1-a):Proposer 发送 Prepare
Proposer 生成全局且递增的提案 ID(Proposalid,以高位时间戳 + 低位机器 IP 可以保证性和递增性),向 Paxos 集群的所有机器发送 PrepareRequest,这里无需携带提案内容,只携带 Proposalid 即可。
P1-b):Acceptor 应答 Prepare
Acceptor 收到每一个PrepareRequest 后,根据“两个承诺,一个应答”。
两个承诺
承诺一,Acceptor不再应答Proposer发出的 Proposalid 小于等于(注意:这里是 <= )当前请求的 PrepareRequest; – –> 第一阶段的承诺,响应PrepareResponse,貌似响应中也应为目前无接受值而只是包含Proposalid
承诺二,Acceptor不再应答Proposer发出的 Proposalid 小于(注意:这里是 < )当前请求的 AcceptRequest; – –> 第二阶段的承诺,响应AcceptResponse
承诺接收最新提案且废弃旧提案
一个应答
若传入的提案的编号大于它已经回复的所有 prepare 消息,则Acceptor返回自己已经 Accept 过的提案中 ProposalID 较大的那个提案的内容(已批准过最大值),如果没有则返回空值;
应答当前请求前,也要按照“两个承诺”检查,且Acceptor应答前要在本地持久化当前响应的Propsalid。
在Prepare阶段,Acceptor可以不停的根据上面的两个承诺进行应答。把自己已经应答过的历史值返回给Proposer,这样Proposer就可以对历史的最大提案值重新作为提案内容。
第二阶段 Accept
当一个 Proposer 收到了多数 Acceptors 对 prepare 的回复后,就进入批准阶段。P2-a):Proposer 发送 Accept
“提案生成规则”:Proposer 收集到第一阶段多数派应答的 PrepareResponse 后,从中选择proposalid最大的提案内容,作为要发起 Accept 的提案,如果这个提案为空值,则可以自己随意决定提案内容,否则获取在prepare阶段响应中的最大的Proposalid的value,然后加上当前 Proposalid,向 Paxos 集群的所有机器发送AccpetRequest<Proposalid,value>。
此时要不就是初始阶段携带了自己值,要不就是携带了某个Acceptor接受的最大提案编号以及对应的值
P2-b):Acceptor 应答 Accept
Accpetor 收到 AccpetRequest 后,检查不违背自己之前作出的“两个承诺”情况下,持久化当前 Proposalid 和提案内容,若此时在半数中有新的协议版本>当前版本,则将返回新的AcceptResponse。最后 Proposer 收集到多数派应答的 AcceptResponse 后,形成决议。
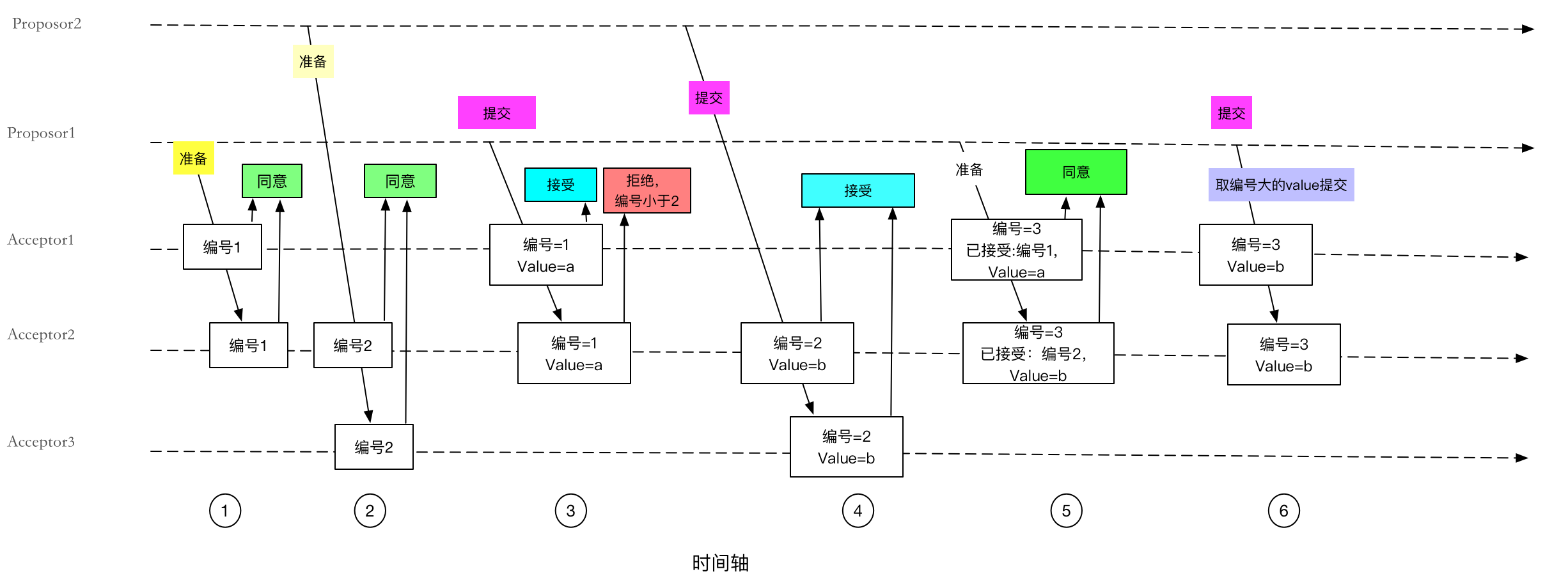
简单示例
引用paxos原理分析简单图解示例
Multi Paxos
Basic-Paxos 只是理论模型,在实际工程场景下,比如数据库同步 Redolog,还是需要集群内有一个 leader,作为数据库主机,和多个备机联合组成一个 Paoxs 集群,对 Redolog 进行持久化。
Question
- 如果靠提议ID的大小决定,那岂不是谁的大谁就会被接受,可不可能不应该被接受的使用最大id。
- 想获得过半响应,则需要等待多久?
Raft算法
引入主节点,通过竞选。
节点类型:Follower、Candidate 和 Leader,Leader 会周期性的发送心跳包给 Follower。每个 Follower 都设置了一个随机的竞选超时时间,一般为 150ms~300ms,如果在这个时间内没有收到 Leader 的心跳包,就会变成 Candidate,进入竞选阶段。
流程
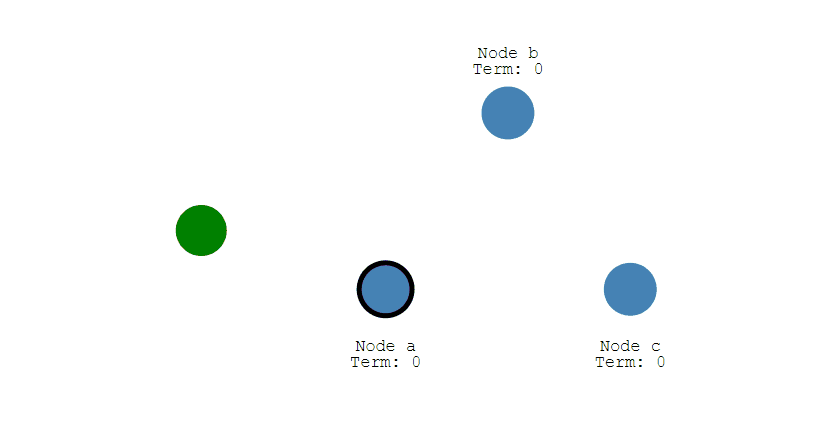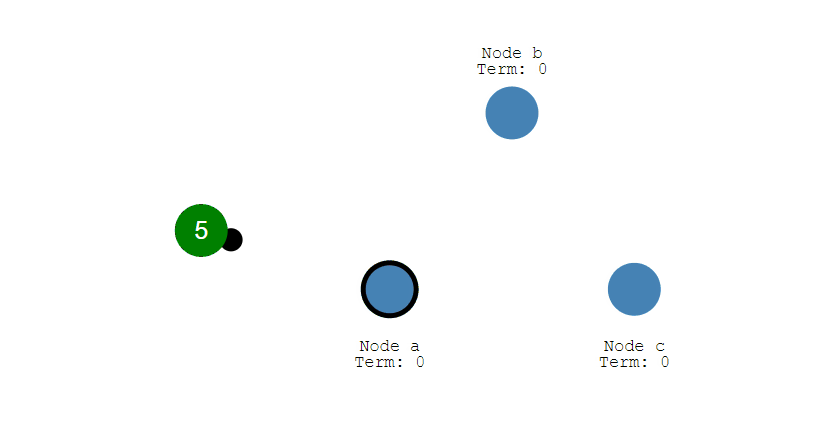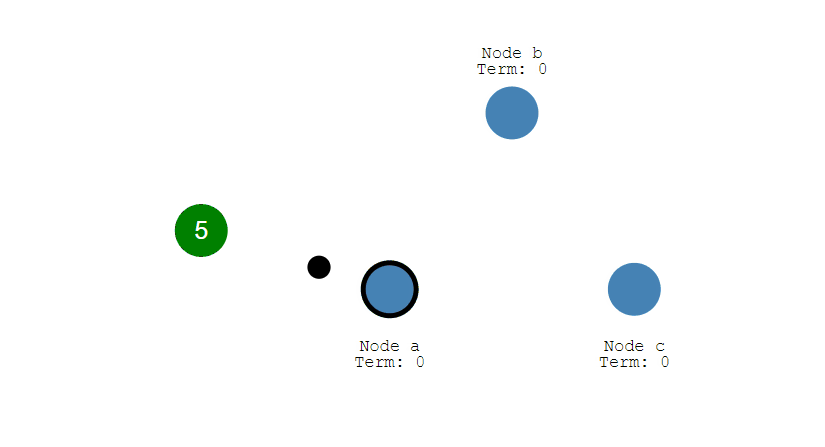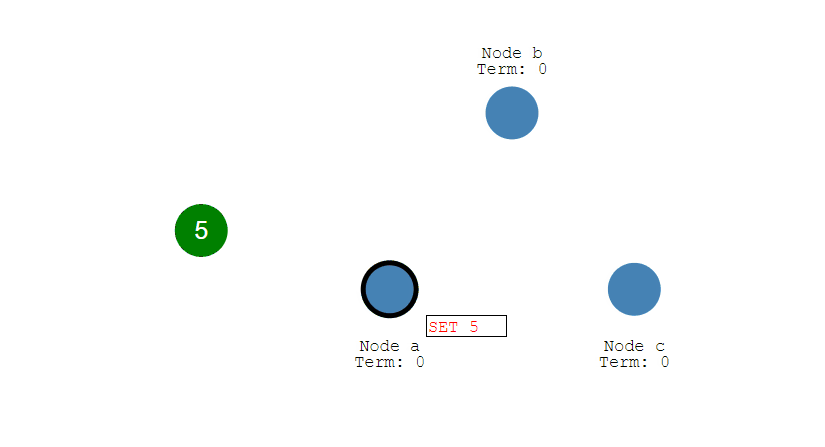
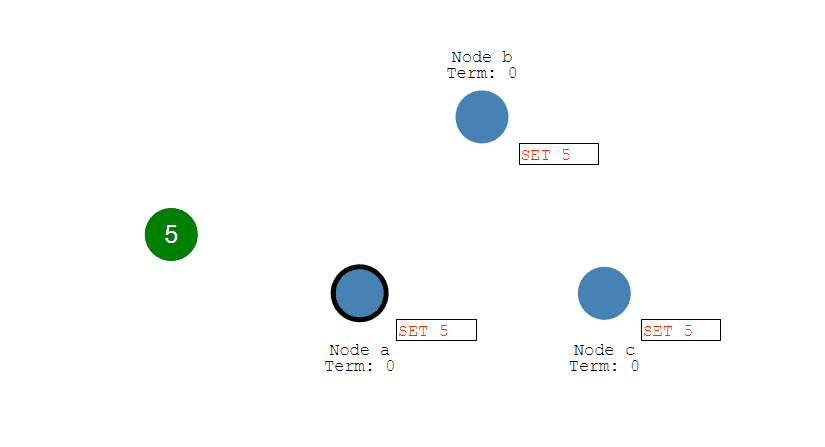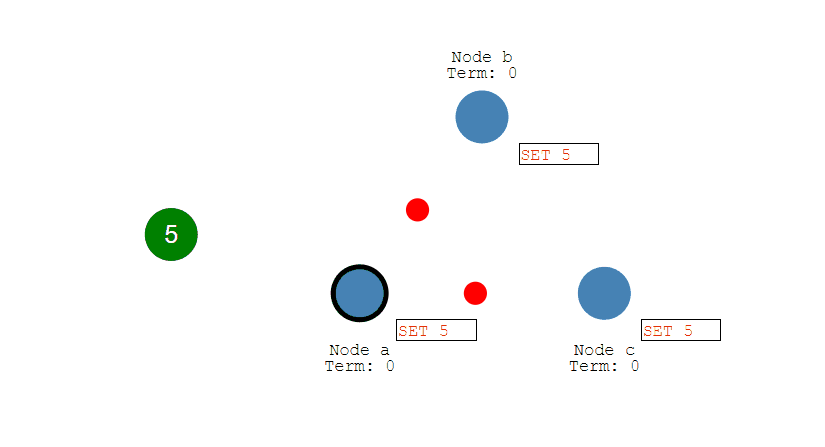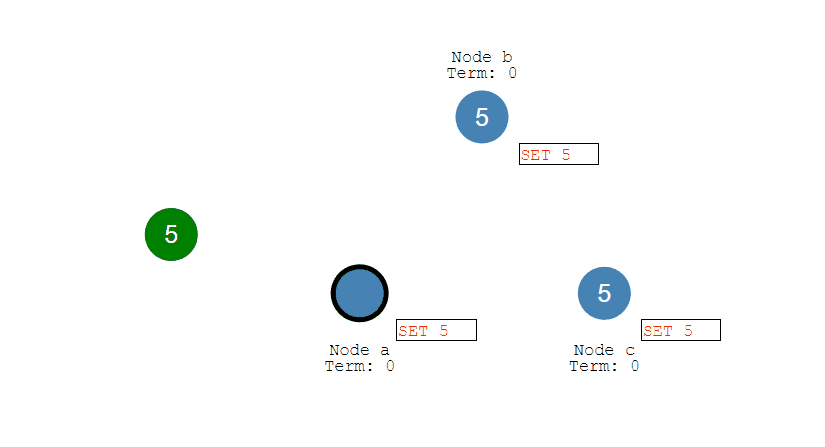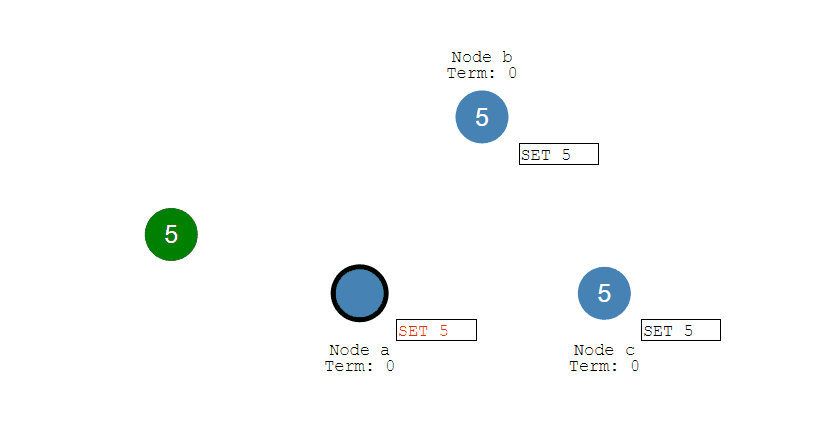
最初阶段,此时只有 Follower,没有 Leader。Follower A 等待一个随机的竞选超时时间之后,没收到 Leader 发来的心跳包,因此进入竞选阶段。
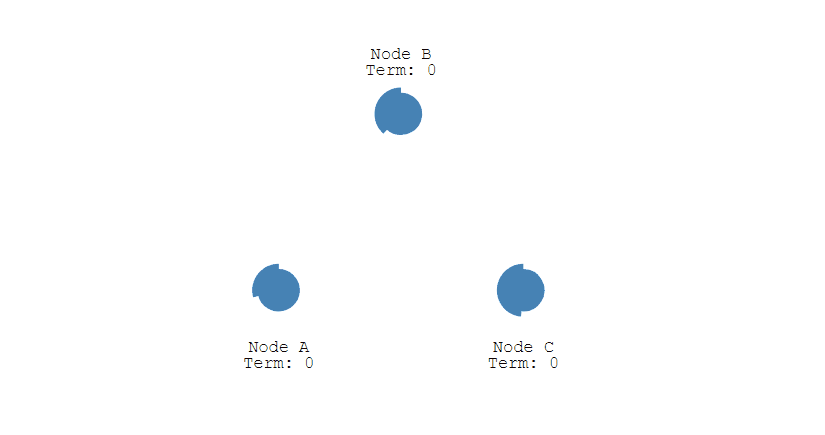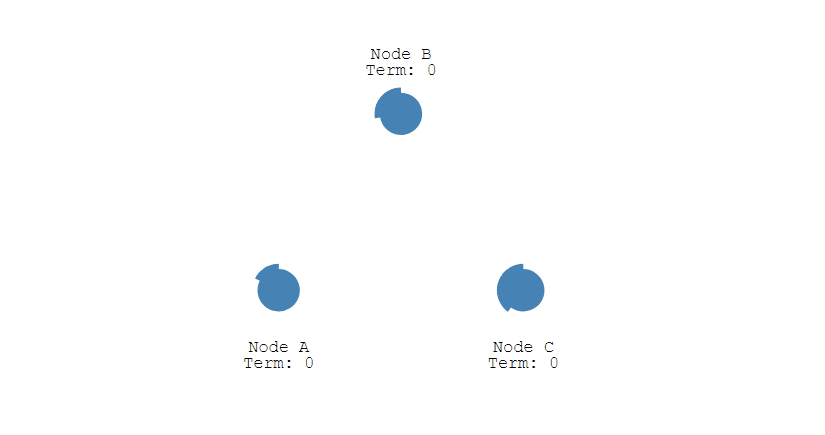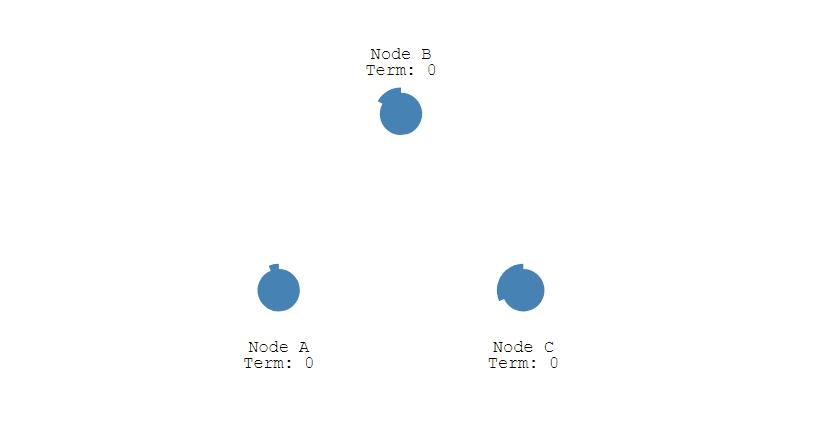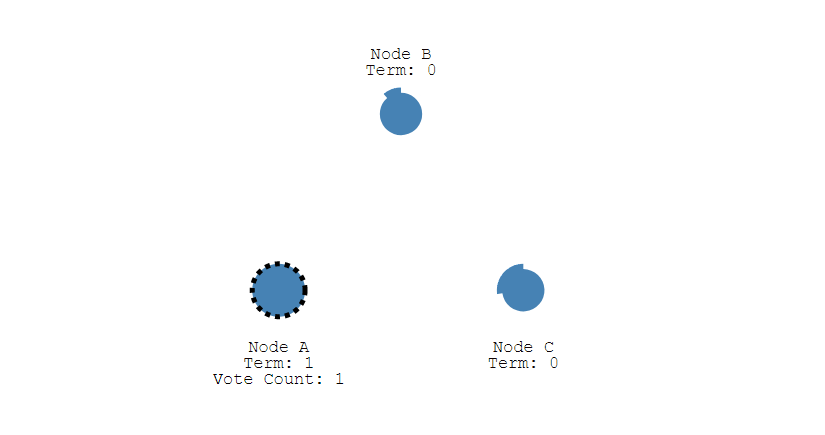
此时 A 发送投票请求给其它所有节点。
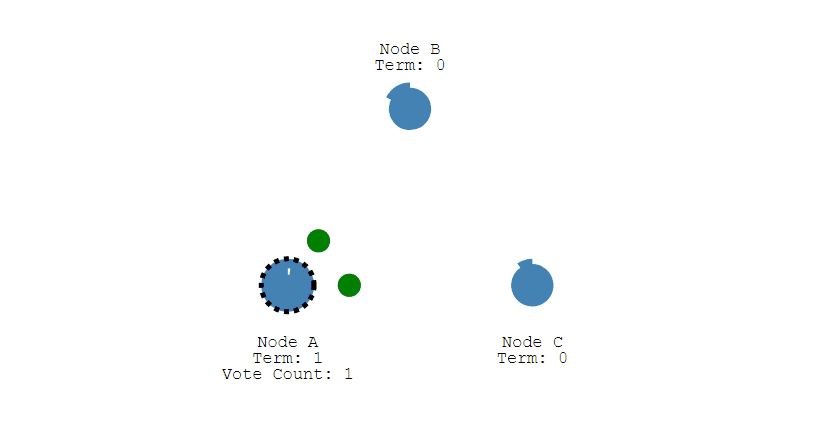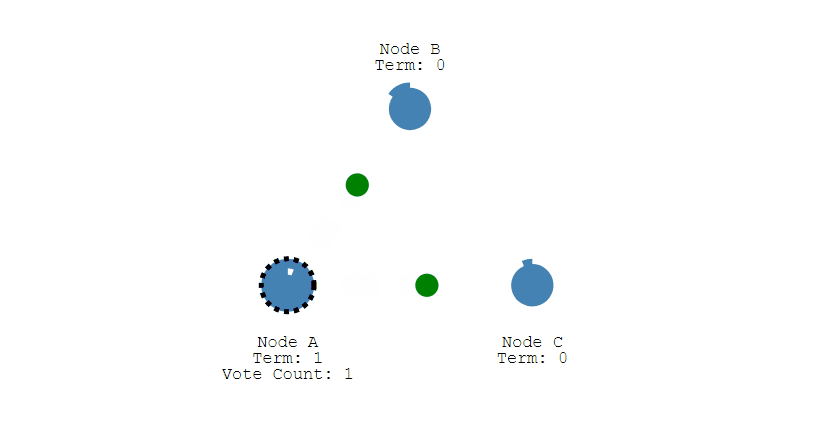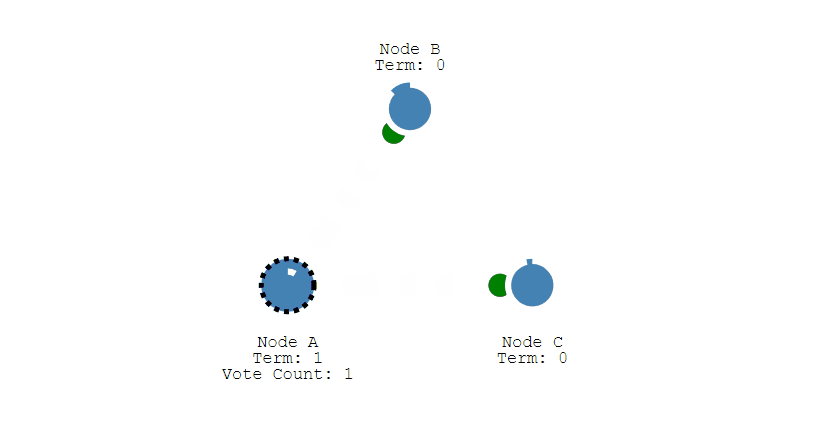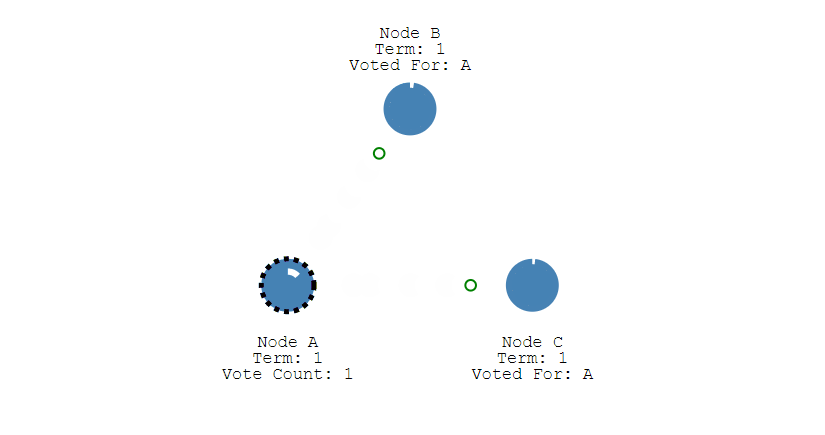
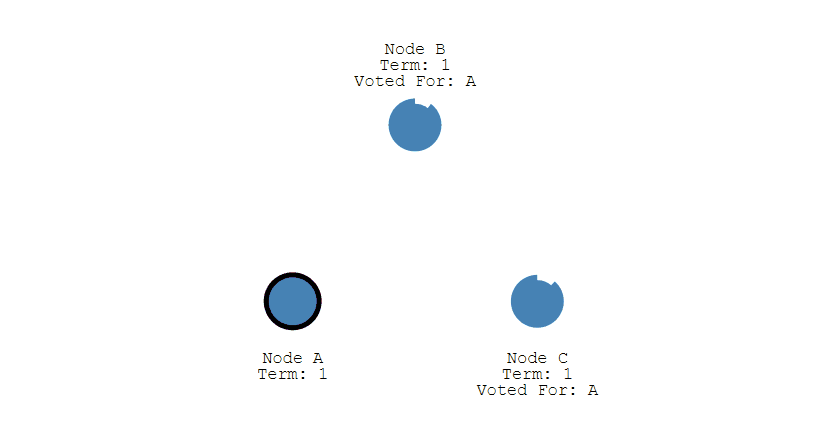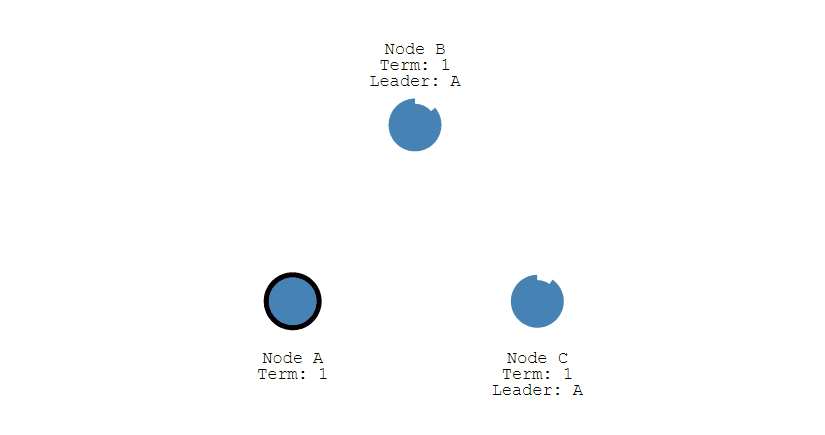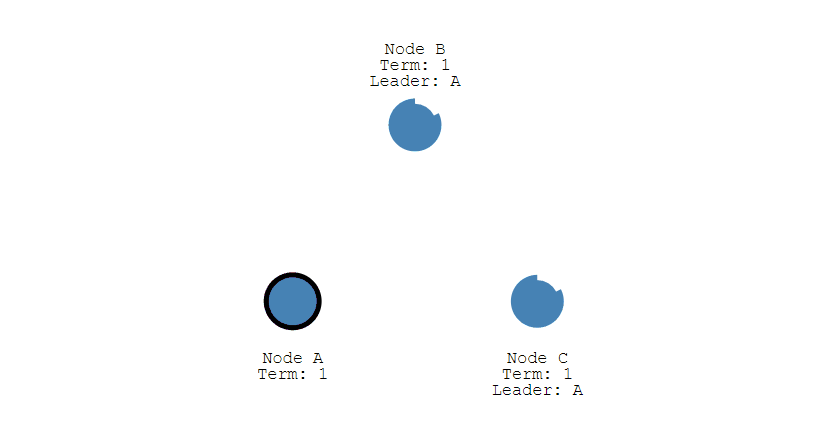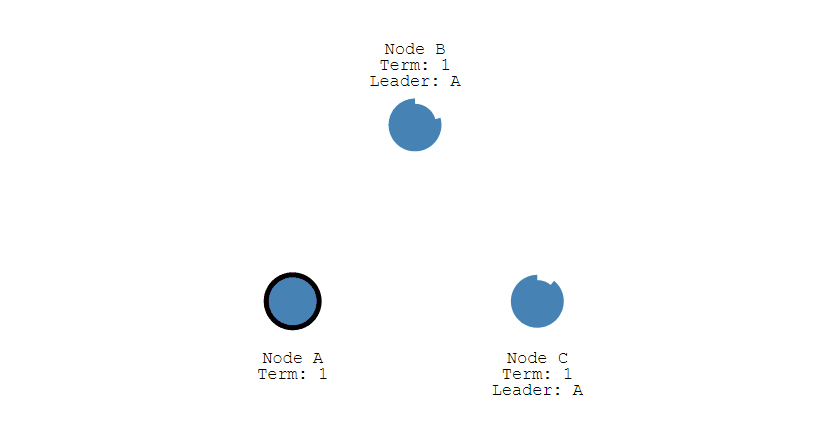
其它节点会对请求进行回复,如果超过一半的节点回复了,那么该 Candidate 就会变成 Leader。
之后 Leader 会周期性地发送心跳包给 Follower,Follower 接收到心跳包,会重新开始计时。
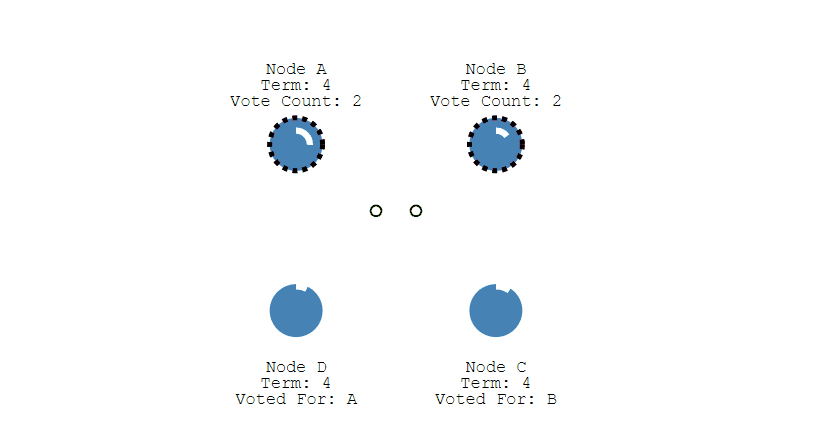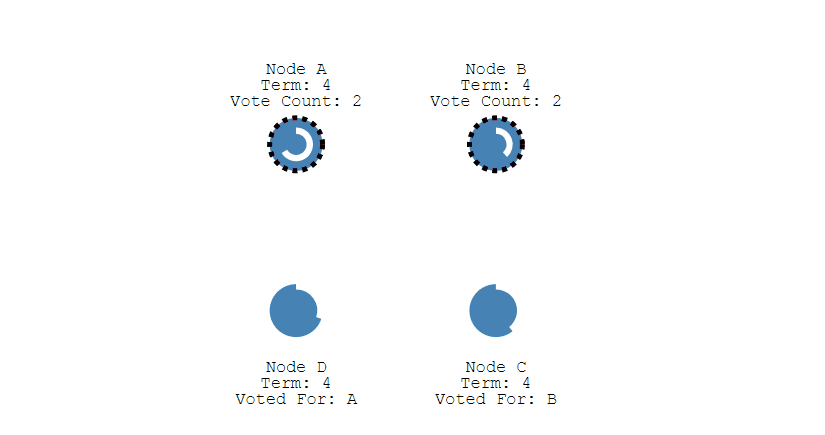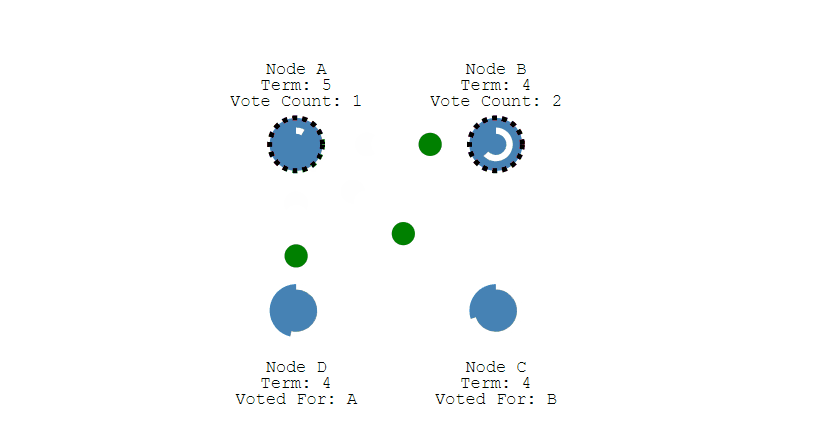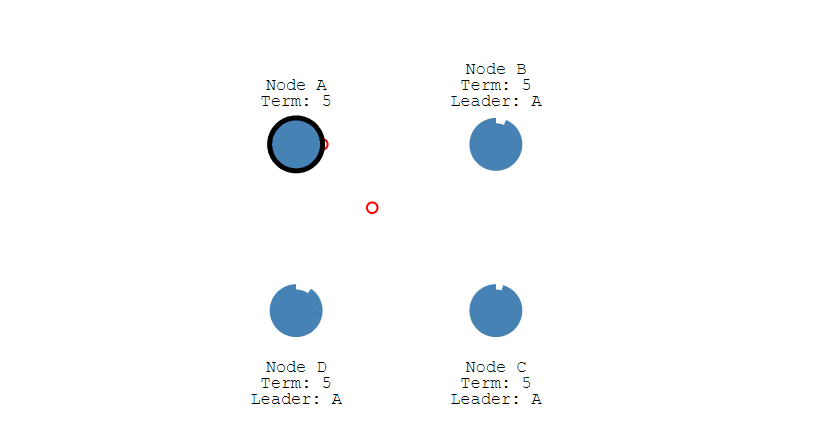
多个 Candidate 竞选
如果有多个 Follower 成为 Candidate,并且所获得票数相同,那么就需要重新开始投票,例如下图中 Candidate B 和 Candidate D 都获得两票,因此需要重新开始投票。
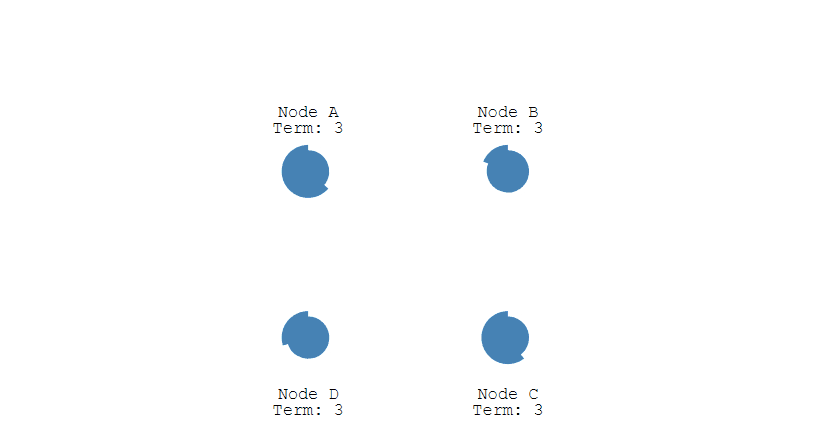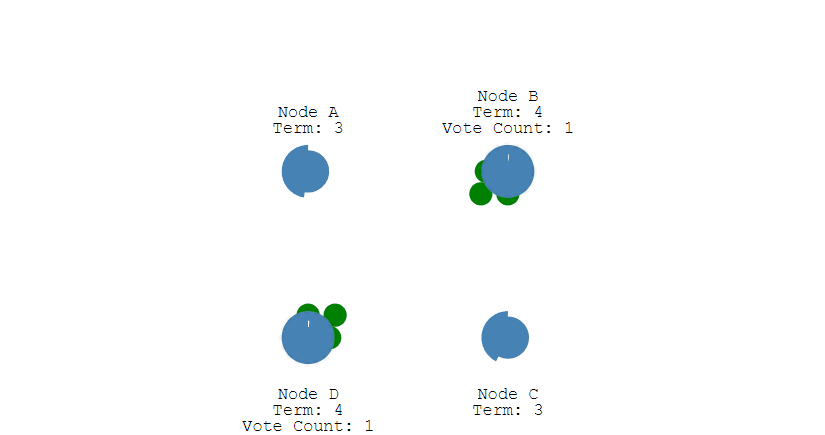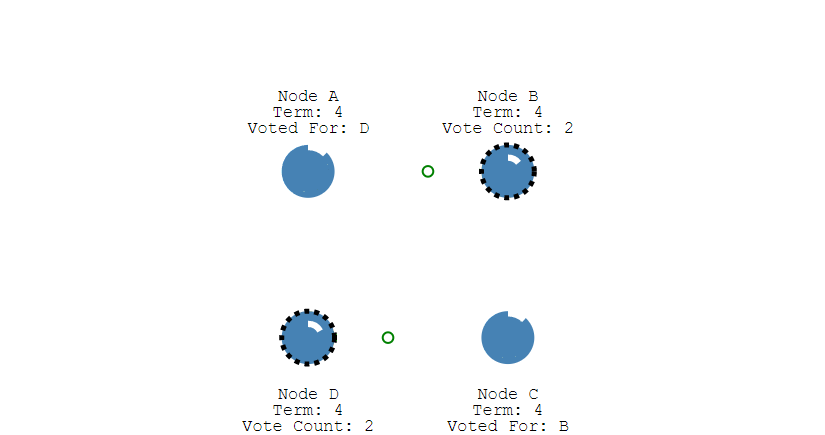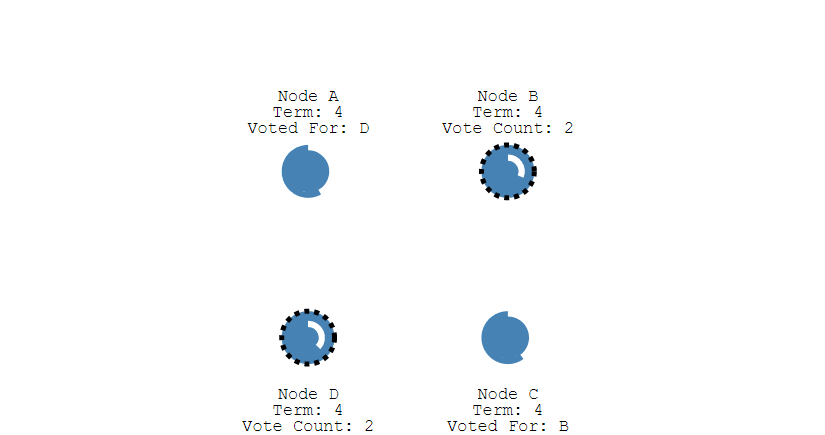
当重新开始投票时,由于每个节点设置的随机竞选超时时间不同,因此能下一次再次出现多个 Candidate 并获得同样票数的概率很低。
日志复制
来自客户端的修改都会被传入 Leader。注意该修改还未被提交,只是写入日志中。
 Leader 会把修改复制到所有 Follower。
Leader 会把修改复制到所有 Follower。
 Leader 会等待大多数的 Follower 也进行了修改,然后才将修改提交。
Leader 会等待大多数的 Follower 也进行了修改,然后才将修改提交。
 此时 Leader 会通知的所有 Follower 让它们也提交修改,此时所有节点的值达成一致。
此时 Leader 会通知的所有 Follower 让它们也提交修改,此时所有节点的值达成一致。
 最后,领导者向客户端返回日志写入成功的响应消息。
最后,领导者向客户端返回日志写入成功的响应消息。
日志格式
在Raft算法中,实现分布式一致性的数据被称为日志(log)。日志记录按照时间顺序进行追加,确保顺序一致性。在Raft算法中,日志以特定的格式写入日志文件,并严格按照时间顺序进行记录。通过这种方式,Raft算法保证了数据的可靠性和一致性。
下面这张图就描述了Raft集群中日志的组成结构:
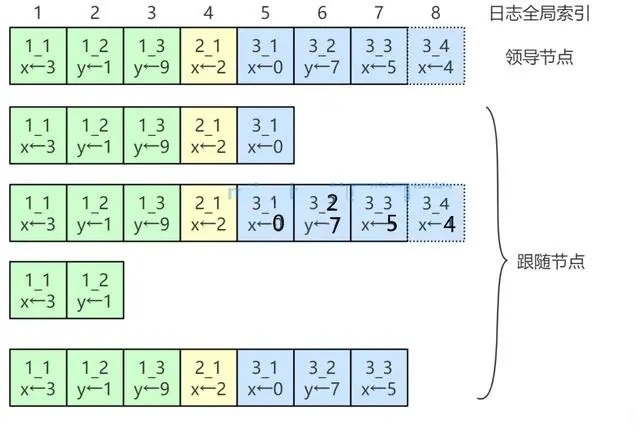 在Raft算法中,每个小方框表示一个日志条目(entry),每个日志条目包含一条命令(command)、任期编号(term)、日志条目在日志中的位置信息(索引值LogIndex)。
在Raft算法中,每个小方框表示一个日志条目(entry),每个日志条目包含一条命令(command)、任期编号(term)、日志条目在日志中的位置信息(索引值LogIndex)。
- 命令:由客户端请求发送的执行指令,可以理解为客户端需要存储的日志数据。
- 索引值:表示日志条目在日志中的位置,它是一个连续且单调递增的整数。
- 任期编号:指的是创建该日志条目的领导者的任期编号。这个任期编号用于标识在哪个任期内该日志条目被创建。
Raft 在集群日志不一致时的 Leader 选举原理,Raft中承诺一个Term中一旦投票给某个节点后,将不在投票给其他节点,当不同Term节点都认为自己是Leader时,只要有一个 Leader 能及时用心跳/日志同步占据大多数,其他节点会识别到 term/Leader 冲突,回退成 Follower,只认更大 term/最新 Leader(即使较低的被承认过也会被替换)。
Raft 选举问题场景精化
- 假设总共 5 个节点(N=5,需要大多数>=3投票才能当选 Leader)。
- 节点日志分布如下:
| 节点 | lastLogIndex/lastLogTerm |
|---|---|
| A | 3 |
| B | 3 |
| C | 3 |
| D | 4 |
| E | 5 |
- 抛出问题:节点 D(日志为4)Timeout最先发起选举,向全体请求投票
若大多数节点(A、B、C)的日志都 ≤3,是否会投票给日志为4的 D,使得日志为5的节点 E 永远无法选出来?
Raft 选举日志新鲜度细节
Raft 的日志新鲜定义:投票时只比较 候选者 与 投票者自己 的日志新旧。
- Raft规定:“投票节点只会给日志‘不比自己老’的Candidate投票。”
- 不是和集群最全日志比较,只和自己比较!
分析投票过程
1. 节点 D 发起选举
- D 的(4) >= A/B/C 的(3),A B C 都会投票给 D(因为 D 的日志比他们新)。
- D 自己也可以投自己一票。
- D 得到 4 票(D, A, B, C),则直接当选Leader。
2. 节点 E 在下一个 term 发起选举尝试
- E 的 lastLog 5,比 D 的 4 新。
- 但是此时 D 还是 Leader,只要 D 不挂、网络未分区,E 不会有机会成为 Candidate 并拉票。
-
如果 D Down 机或失去 Leader 身份,E 有机会发起选主。
- 如果 E 拉票,A/B/C 的 lastLog 仍是 3,E >= 他们,A/B/C 会投票给 E。
- D 的 lastLog 是 4,E 的 5 > 4,也会投。
- 所以只要 E 能发起选主,是有机会成功的。