kafka利用zk临时节点特性从所有broker中选举出一个controller节点,controller节点会负责一些管理工作,如监听broker变化、监听topic变化、监听分区变化,管理分区信息等。
kafka对topic分区采用多副本机制来保障消息存储的可靠性,leader分区负责读写,follower仅负责从leader拉取数据做同步保障。因此分区的数量必须小于等于broker的数量且kafka会尽量保障每个broker所负责的分区数量达到一个均衡。当leader 异常时,kafka会从与leader保持同步度高的副本(ISR)中选举一个新的leader。并在进行消息同步处理之后继续向外提供服务。
整体结构图:
kafka从整体上来看,是一种无主的(节点之间相互协调管理)服务,每个消息通过内部Topic路由,路由到主partition中去,也即高可用是用过内部partition的主从副本模式而不是整个服务主从模式来先实现。
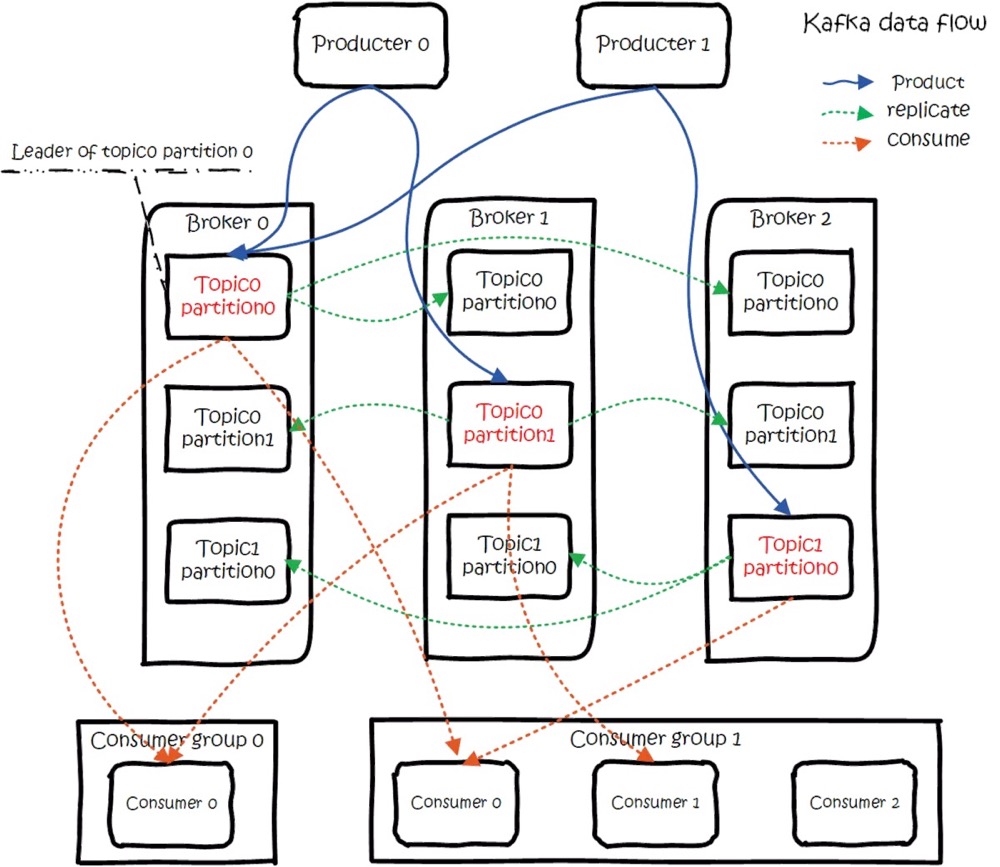
图中有两个topic,topic 0有两个partition,topic 1有一个partition,三副本备份。可以看到consumer gourp 1中的consumer 2没有分到partition处理。
kafka的数据,实际上是以文件的形式存储在文件系统的。topic下有Partition,同一Topic下的不同分区包含的消息是不同的。partition下有segment,segment是实际的一个个文件,topic和partition都是抽象概念。每个segment文件大小相等,文件名以这个segment中最小的offset命名,文件扩展名是.log;segment对应的索引的文件名字一样,扩展名是.index。
Kafka ISR机制提供更强写入一致性(选择CP),需要ISR全部副本确认,但在极端或网络抖动情况下,如果副本数量不足,将拒绝服务,所以可能影响写入的持续可用性
| 消息队列特性 | Kafka(重视强一致性) | RocketMQ(重视高可靠性和业务连续性) | ||||
|---|---|---|---|---|---|---|
| 写入确认机制 | 需要ISR全部副本确认,确保数据写入强一致性 | 支持同步和异步复制,灵活权衡写入延迟与数据可靠性 | ||||
| 故障恢复能力 | ISR副本不足时可能拒绝写入,影响系统短暂可用性 | 拥有重试和轨迹机制,保证消息不丢失,支持事务确保业务完整性 | ||||
| 适用业务场景 | 适合大数据流或实时分析场景,对一致性和实时性要求高 | 适用于事务性业务或金融场景,对消息可靠性和业务流程完整性要求极高 | ||||
| 容错策略 | 强调强一致性,可能牺牲部分延迟和短暂不可写入性 | 注重业务不中断和消息高可靠投递,灵活应对各种故障情况 | Kafka( | 重视高可靠性和业务连续性)确认** ISR副本, 支持同步和异步复制, ISR不足可能写入影响系统短暂可用性 | 保证消息不丢失,**流实时场景对一致性和实时性要求高 | 对消息可靠性和业务流程完整性要求极高 |
controller
kafka集群会选出一个broker作为controller,早期版本这个选举是借助zookeeper来完成的,zookeeper本质是通过让它们抢占一个临时节点(/kafka/controller),谁抢到谁就是controller。
在早期的2.0版本中,controller选举依赖zk,但是3.0中开始弱化zk作用,可以通过配置直接指定或者RaftController来实现。
对于创建 Topic 这种会更改集群元数据的请求,在 KRaft模式下都会交给 Kafka Controller集群的 Leader 节点处理。元数据保存下来后必然要传播到整个集群,使其正常生效,这个传播的过程就是元数据的主从同步。 阅读参考-Kafka 服务端元数据的主从同步
kafka中的Topic元数据信息存储在ZK的持久节点中,这些节点记录了ZK的元数据描述了Topic的分区的信息,记录了具体的Leader,副本数等信息。
注意:controller是在Broker端的,Coordinator也是在Broker端的,客户端只会与Broker链接而不会与controller直接连接。
Topic&Partition分区
发送端
- 可以将Topic理解为逻辑表,而Partition理解为物理库(分库),segment理解为具体的物理表。
- kafka的消息为k,v键值对形式,其中key也是默认为null。
- 在默认情况下,随机发送到一个Partition分区下。在参数”metadata.max.age.ms”的时间范围内随机选择一个时间段值,在这个时间段内,如果 key 为 null,则只会一直发送到唯一固定分区。这个时间段值默认情况下是 10 分钟更新一次。
- 在key不为null时,若不指定分区,则这种情况下其通过key hash取模/partition数量(可以自定义实现Partitioner接口)来决定存放在具体的哪个Partition 。
- 如果既没有指定分区,且消息的key也是空,则用轮询的方式选择一个分区。
消费端
- 在消费端可以设置分区来使特定的consumer消费特定的Partition分区,示例代码:
1 2 3 4 5
//消费指定分区的时候,不需要再订阅 //kafkaConsumer.subscribe(Collections.singletonList(topic)); //消费指定的分区 TopicPartition topicPartition=new TopicPartition(topic,0); kafkaConsumer.assign(Arrays.asList(topicPartition));
- 若不指定,则有两种方式来产生对应关系,两种方式通过partition.assignment.strategy这个参数来设置
消费端管理总结:
1、每个消费组由 Kafka 集群中一个特定的 Broker 承担 Group Coordinator 角色。
2、该 Coordinator 负责管理该消费组的成员状态、心跳检测、分区分配和 offset 维护。
3、Coordinator 的信息都存在特殊的topic中,所以转移后信息不会丢失
4、消费组的Coordinator 所在broker时效后,消费者/客户端发现无法与该 Broker 正常通信会触发 元数据刷新(Metadata Refresh),获取最新 Broker 列表,消费者会根据最新的broker信息进行转移获得对应的 Coordinator
5、Coordinator只维护元数据信息,消费者客户端根据自己本地实现的策略,进行Consumer leader协调者的管理(不跨网让Coordinator去管),这样更加灵活也是业务逻辑下推到更贴近数据的一端
Partition分区
Replication逻辑上是作用于Topic的,但实际上是体现在每一个Partition上。
一个分区就是一个提交日志,消息以追加的方式写入分区,然后以先入先出的顺序读取。
由于一个主题包含多个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
kafka 也是通过分区来实现数据冗余和伸缩性(一个Topic可以通过多个分区并分布在不同服务器上的方式,横跨多个服务器)。
一个broker存在0~N个分区,borker与分区关系计算公式:
1
2
对于总量为N的Broker,第i个分区位置:
int pos = i mod N
Partition分区个数设置
通过在脚本启动时设置”–partitions”或在配置文件中设置”num.partitions”来规定Partition分区个数
Consumer访问Partition分区方式
A.Range方式(默认)
这种情况下对若Topic发送分区固定,则消费者也固定。举例说明:
如果我们有 10 个分区,3 个消费者线程, 10 / 3 = 3,而且除不尽,那么消费者线程 C1-0将会多消费一个分区。
B.RoundRobin方式(轮询)
轮询分区策略是把所有 partition 和所有 consumer 线程都列出来,然后按照 hashcode 进行排序。最后通过轮询算法分配 partition 给消费线程。
Partition分区数量与Consumer配置建议
kafka存在特性:一个分区只能被一个Group中的一个消费者进行消费;
上面这个特性决定了当一个Group下的消费者数量超过分区数量时,多余的消费者将处于闲置状态。
– 数量设置建议:分区数量为Consumer数量的整数倍。
reBalance
Kafka保证同一consumer group中只有一个consumer会消费某条消息,当消费者发生变化,消费者与Partition的对应关系发生变化称之为reBalance.
分区对应的消费者发生变化时将会触发该过程:
- 对于同一个Group来说,当其消费者数量变更(新增、摘除)时将会被触发。
- 当分区数量发生变化时,该分区下面的所有Group将触发reBlance操作。
reBalance的执行以及管理 consumer 的 group
Group Coordinator
Group Coordinator充当了执行和管理的角色,其与Broker维持了心跳和定期检测最新元数据,当Broker/消费组中发生变更时能感知到,注意coordinator是消费者组的。
如何产生:消费者向kafka集群中任意一个broker发送一个GroupCoordinatorRequest 请求,服务端会返回一个负载最小的broker节点的id ,并将该broker设置为coordinator。
消费端Group的产生
一旦存在coordinator后,消费端所有成员都会向coordinator发送 joinGroup 请求,该请求携带了自己的信息和要加入的组信息。所有成员发送完毕后, coordinator会决策选取一个Consumer作为该组的Leader,并将相关信息:组ID、成员列表(Leader才有)、Leader、generation_id(年代信息)、protocol_metadata(消费者的订阅信息)同步给所有Consumer。其中,generation_id为递增的主要用来保护 consumer group。隔离无效的 offset 提交。也就是上一轮的 consumer 成员无法提交 offset 到新的 consumer group 中。
集群分区消费方案确定
所有的消费者均向coordinator发送SyncGroupRequest请求(实际中只有leader的发送携带了分区消费方案,其它都是酱油)。coordinator 接受到请求后会把结果设置到 SyncGroupResponse 中并返回给每一个消费者 –由此可以看出,其实消费方案是在客户端制定的,这样权利下放给客户端可以更加的灵活。
Offset管理
Kafka中的每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中,对于某个partition,其维护了自身的一个自增offset。partition中的每个消息都有一个连续的序号,用于partition唯一标识一条消息。Offset从语义上来看拥有两种:Current Offset和Committed Offset。
-
Current Offset
其存储在Consumer端,每表示Consumer希望收到的下一条消息的序号,仅在pull方式中使用,例如,Consumer第一次使用pull拉取了20条数据,则Consumer本地记录了Current Offet被设置为20,下次拉取时将20传递给kafka。 -
Committed Offset
保存在Broker上,它表示Consumer已经确认消费过的消息的序号,当消费者获取消息后宕机等不确认,则Committed Offset保持不变。
Committed Offset主要用于Consumer Rebalance。在Consumer Rebalance的过程中,一个partition被分配给了一个Consumer,那么这个Consumer该从什么位置开始消费消息呢?答案就是Committed Offset,当新启动时,kafka返回从Committed Offset开始的消息,这样避免重复消费。
Committed offset维护
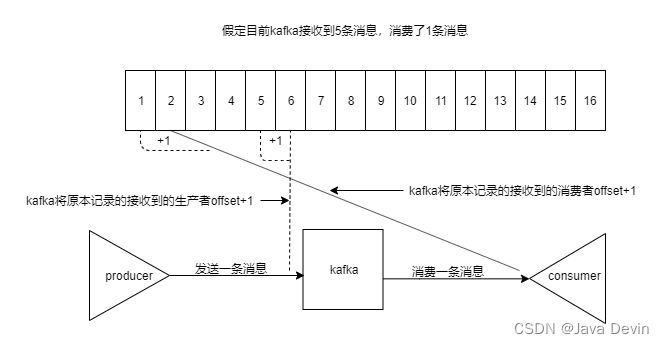
kafka消费者会保存自己的消费进度,也就是offset。存储的位置根据消费组选用的kafka api不同而不一样。
- javaapi:消费者的offset会更新到zookeeper中;
- kafka默认的api:消费者的offset会更新到一个kafka自带的topic【__consumer_offsets】下面。提供了一个__consumer_offsets 的一个topic,把offset信息写入到这个topic 中。__consumer_offsets 一一的保存了每个 consumer group某一时刻提交的 offset 信息(消费确认)。__consumer_offsets 默认有50 个分区,每个消费组offset信息存储所在分区对应关系计算公式:
1
2
3
int value = Math.abs("groupid".hashCode())%groupMetadataTopicPartitionCount ;
//其中,groupMetadataTopicPartitionCount默认为50.
//若value为15,那么表示__consumer_offsets-15,即其第15个分区保存了groupid该分组的offset信息。
consumer 消费了数据之后,每隔一段时间(定时定期),会把自己消费过的消息的 offset 提交一下,
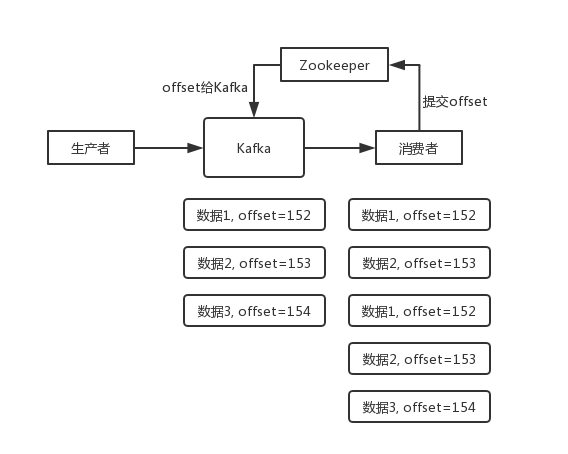
由于一个partition只能固定的交给一个消费者组中的一个消费者消费,因此Kafka保存offset时并不直接为每个消费者保存,而是以groupid-topic-partition -> offset的方式保存。offset日志格式为:
1
[Group, Topic, Partition]::[OffsetMetadata[Offset, Metadata], CommitTime, ExpirationTime]
信息中存储了[grouoId、Topic、信息所在PartitionId分组号、当前offset值、CommitTime、过期时间]。
更详细参考请见:Kafka offset管理
Metadata
broker是有状态的服务:每台broker在内存中都维护了集群上所有节点和topic分区的状态信息–Metadata
简单理解就是Topic/Partition 和 broker 的映射关系,每一个 topic 的每一个 partition,需要知道对应的 broker 列表是什么,leader 是谁、follower 是谁。这些信息都是存储在 Metadata 这个类中。
- 生产者/消费者的clients并不是时刻都需要去请求元数据的,且会缓存到本地;
- 即使获取的元数据无效或者过期了,clients通常都有重试机制,可以去其他broker上再次获取元数据;
- cache更新是很轻量级的,仅仅是更新一些内存中的数据结构,不会有太大的成本。因此我们还是可以安全地认为每台broker上都有相同的cache信息。
只要集群中有broker或分区数据发生了变更就需要更新这些cache,比如当有新的borker加入时,其它broker监听Zookeeper的controller就会立即感知这台新broker的加入去更新缓存。
在高版本中,不依赖zk,而是使用 Raft 协议来实现元数据的管理。RaftController 是 Kafka 集群中的关键组件,它会选举一个Controller Leader使用 Raft 一致性协议来维护集群的元数据,包括主题、分区、副本分配、Leader 选举等,该 Leader 负责处理元数据的变更请求,并将这些变更同步给其他 Broker。
客户端在初始建立连接时,会从Broker获取到元数据信息,并且定时更新&被Broker通知变更。
消息存储原理
LogSegment
我们知道Topic是以Partition为基本的存储单元存放在Broker中,其实在实际的物理存储中,一个Partition log日志文件被划分为多个LogSegment。LogSegment也为一个逻辑单元,其由四部分组成:
- .log
- .index,消息offset与磁盘物理偏移的排序索引文件
- .timeindex
每个Partition被均匀的且分为多个Segment中,显然这样方便kafka消息文件的维护和被消费消息的清理。通过设置log.segment.bytes参数来控制切分的log日志文件大小,默认为107370.
segment 文件命名规则:Partion 全局的第一个 segment从 0 开始,后续每个 segment 文件名为上一个segment文件最后一条消息的 offset 值进行递增
segment 中 index 和 log 的对应关系
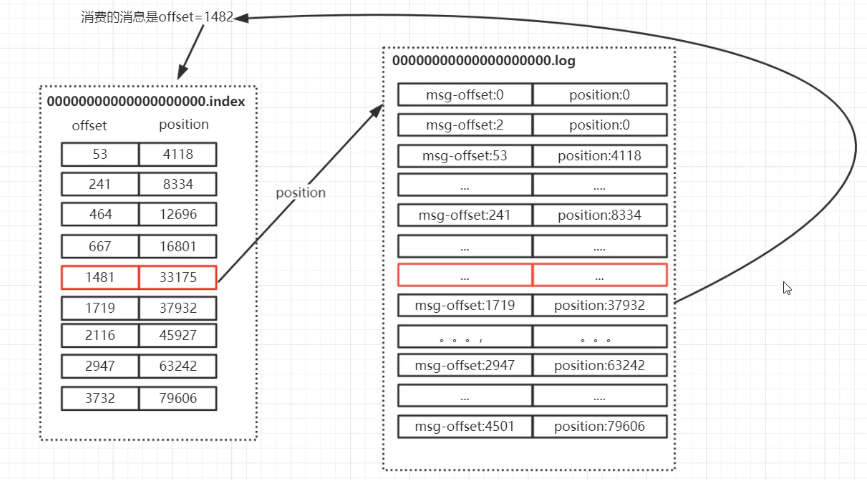
如图所示,index 中存储了索引以及物理偏移量(key=offset,value=prosition)。.log存储了消息的内容。索引文件的元数据执行对应数据文件中message的物理偏移地址。举个简单的案例来说,以index文件中一条记录[1482,33175]为例,在log 文件中,找到物理(磁盘)偏移量(position)为 33175 的值,然后在值列表中查找其对应的msg-offset值,该值即为具体的消息内容。
position 是ByteBuffer 的指针位置。
Question:
1、什么时候采样放入到index文件中:目前个人理解在进入一个新磁盘页的时候,将进入的第一个数据存放进去。
2、为什么index文件中offset和partition都是有顺增长的:这个很好理解,offset是Partition的整体自增键,每来一条消息该Partition的offset自增一次,同样,partition对应了物理磁盘的页,顺序存放数据,所以页号也是自增的。
Partition中如何通过offset查找具体的message
先通过二分查找算法在.index文件中快速定位到具体的磁盘偏移量position(YYY),也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。再通过查找到的position到.log文件中在value=“partition(YYY)”查找对应的消息偏移量:msg-offset值,该值即为具体的消息内容。为啥顺序查找:可以简单理解partition为磁盘页(ByteBuffer)地址,该地址上存储了多个offset对应的消息,所以先定位到具体的页地址,然后在物理页中顺序查找。
数据丢失
一般消费端丢失都是使用默认的自动应答造成的,自动提交了 offset但是在消费时挂了。
发送端可能是没有开启副本同步,leader挂了没有写入全部的副本中。
日志压缩策略
开启 kafka 的日志压缩功能,服务端会在后台启动启动Cleaner 线程池,定期将相同的 key 进行合并,只保留最新的 value 值。比如:对于log文件中存在offset=1和offset=5的两个相同key的message,在消费者只关心 key 对应的最新的 value情况下,offset=1对应的消息内容将被清理掉。
replica冗余备份
Partition在很大程度上能够提高kafka的性能,但是很明显,对于一个分区来说存在着单点问题,一旦当前分区出现问题不可用,那么这部分消息将不可被消费。kafka通过Replica通副本机制来实现冗余备份提高kafka的可用性。
kafka的分区存储在全局上均为副本文件,其存在一个leader副本进行消息的读写请求处理,其他副本则只会从Leader副本同步日志消息(不参与任何的消息处理)。当Leader副本所在的Broker不可用时,则从剩余的Follower副本列表集合中重新选举出来Leader副本继续对外服务。
副本分配算法
- 将所有 N Broker 和待分配的 i 个 Partition 排序;
- 将第 i 个 Partition 分配到第(i mod n)个 Broker 上;
- 将第 i 个 Partition 的第 j 个副本(follower副本?)分配到第((i + j) mod n)个Broker 上;
如何查看副本信息
获取命令:
get /brokers/topics/testTopic/partitions/1/state
➢ {“controller_epoch”:12,”leader”:0,”version”:1,”leader_epoch”:0,”isr”:[0,1]}
可以看出,第0个节点为Leader节点,总共存在0和1两个副本。leader 负责维护和跟踪 ISR(in-Sync replicas , 副本同步队列)中所有 follower 滞后的状态。
消费线程
Kafka 和 RocketMQ 都支持多线程消费,但线程池通常需要用户自行管理和配置,而不是由它们封装好的。
kafka 创建多线程自己去拉取消息,而RocketMq 在接口MessageListenerConcurrently支持多线程消费,在其中自定义线程池去处理拉取到的消息。