整体使用原则
个人理解:Redis其实只适合作为缓存,而不是数据库或是存储。它的持久化方式适用于救救急啥的,不太适合当作一个普通功能来用
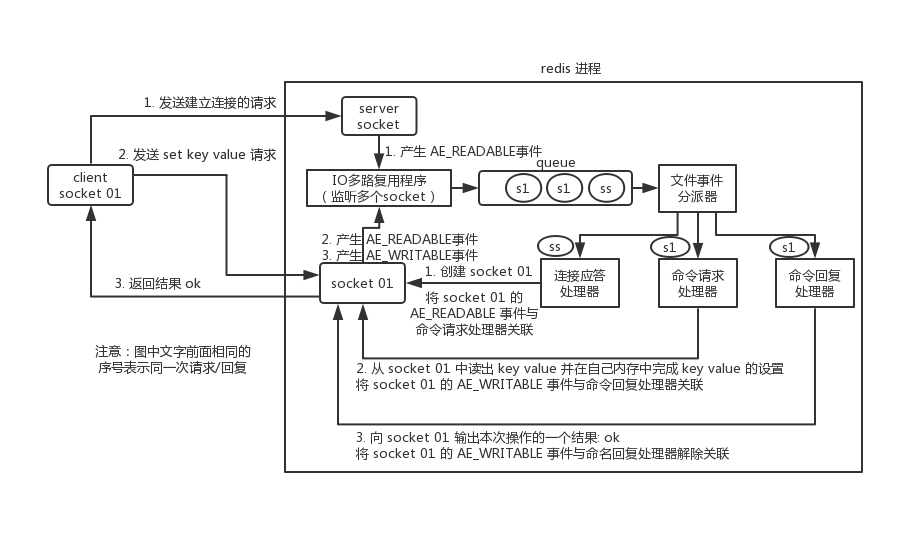
客户端与 redis 的一次通信过程:
集群管理总结:无中心化架构
1、Redis Cluster 模式使用分片+master-slave模式构建集群结构;
2、Gossip 协议定期所有节点之间交换节点状态,当一个主节点被多数Slave节点认为不可达时,被判定位客观下线;
3、主节点下线后,从节点之间先对比谁更适合晋升为新的主节点(比如复制偏移量最大的从节点优先),然后将向集群中其他节点发起投票请求,获得多数节点认同后,晋升为新的主节点;
4、客户端通过定期同步获取+错误触发机制,来更新本地存储的元数据信息;
Redis常见应用场景
1、会话缓存
2、消息队列
3、活动排行榜or计数
4、发布/订阅消息
5、商品列表、评论表等
数据类型
Redis一共支持五种数据类:string(字符串),hash(哈希),list(列表),set(集合)和zset(sorted set有序集合)。
list
一个有序的列表,按照插入顺序排序。list左为头右为尾,所以rpush为往尾部添加数据,lpop从头部取数据;
1
2
// 往列表的头部(左边)推入一个或多个元素,lpush的l表示left。key是列表名称,把列表中的所有元素作为一个整体(value)。若key不存在,会自动创建。
lpush key value1 value2 .....
- 一对多的关系存储,以粉丝列表为例,被关注者的id为key,所有粉丝的id为value存储在Redis list中。
- 作为一个外部消息队列使用,有两种方式做优先级处理:
- 方式一:使用一个队列,队列中每个数据元携带优先级,每次放入时使用二分法查找其在整个队列中的位置,直接插入到队列中。–需要自己使用lua脚本实现插入。
- 方式二:使用BLPOP taskList1 [taskList2 ] timeout 阻塞式从这两个队列里面取数据,如果第一个没有再从第二个里面取。–如果timeout设置为0,那么就会无限等待下去。
Sorted zset
通常使用在类似排行榜场景下:
- 外部大数据排序,例如最新消息排序,每次都将最新小消息使用lpush放在最前面。
zset
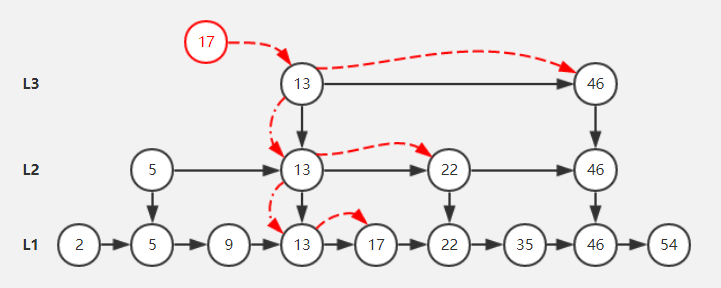
查找时可以进行二分查找的有序链表。
分布式锁的基本特性
- 互斥性,只能加锁者释放锁;
- 无死锁;
- 高可用;
- 重入性;
Redis中有复杂的Set指令配合Lua脚本来实现分布式锁,但推荐直接使用RedLock(需要自己设置超时时间)或者Redission(子线程更新过期时间)。
Redis过期key清理及内存满
如果redis达到设置的内存上限,Redis的写命令会返回错误的信息(命令正常返回),所以推荐作为缓存使用,设置淘汰算法,当Redis达到内存上限时会执行淘汰策略。
Redis对于过期键有三种清除策略:
- 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key;–最大的问题是当key不在被使用时,这种方法下不能被清除。
- 主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key;
- redis中使用serverCron在CPU空闲时定时随机测试一批设置了过期时间的key,若key已过期,则将被删除。
- 当前已用内存超过maxmemory限定,即内存满时,触发主动清理策略:最久未使用/随机释放/马上要过期
- volatile-lru:从设置了过期时间的数据集中,选择最近最久未使用的数据释放;
- allkeys-lru:从数据集中(包括设置过期时间以及未设置过期时间的数据集中),选择最近最久未使用的数据释放;
- volatile-random:从设置了过期时间的数据集中,随机选择一个数据进行释放;
- allkeys-random:从数据集中(包括了设置过期时间以及未设置过期时间)随机选择一个数据进行入释放;
- volatile-ttl:从设置了过期时间的数据集中,选择马上就要过期的数据进行释放操作;
- noeviction:默认,不删除任意数据(但redis还会根据引用计数器进行释放呦~),这时如果内存不够时,会直接返回错误;
缓存一致性
Cache-Aside模式
1
2
3
4
public static void writeData(String key, String value) {
Database.update(key, value);
Cache.delete(key); // 关键:删除而非更新缓存
}
延时双删
1
2
3
4
5
6
7
8
public void updateWithDoubleDelete(String key, Runnable dbUpdate, long delayMs) {
// 第一次删除
redisTemplate.delete(key);
// 更新数据库
dbUpdate.run();
// 延迟第二次删除
scheduler.schedule(() -> redisTemplate.delete(key), delayMs, TimeUnit.MILLISECONDS);
}
缓存穿透与雪崩
缓存穿透
产生原因:正常业务或者恶意请求大量不存在的key。(服务正常,未查询到)
解决方案:
- 对查询结果为空也缓存,并设置一个较短的缓存时间;
- 提前对key进行校验,将非业务查询流量过滤掉;
- 单机中控制并发更新量;
缓存雪崩
产生原因:缓存服务器重启或者缓存失效导致大量请求到后端。(服务不正常,影响面扩散)
解决方案:
- 做二级缓存,在分布式缓存失效的情况下,读取本地缓存;
- 缓存时间随机性,缓存预热、排它锁更新
缓存击穿
产生原因:某个 key 非常非常热,访问非常的频繁,高并发访问的情况下,当这个key在失效流量到后端
解决方案:
- 多级缓存;
- 对缓存打标,对已经/快过期的另外线程更新;
- 排它锁进行访问控制
- 兜底策略,返回兜底值(比如还是旧值),保持若一致性。
Redis持久化
Redis的数据是存在内存中,就需要按照一定的手段将内存中的数据以文件形式存储起来。
- RDB:指定时间间隔后fork一个子进程做全量的数据快照。当数据量较大的时候,可能导致CPU停顿,所以在做备份时需要选择时间点和频率。(默认打开)
- AOF:每次写的操作时,将命令以追加的方式放在AOF文件末尾;(需要手动打开)
对比mysql的主从复制也是类似的命令(statement)/具体数据(rows)同步
为了性能考虑,通常在Master中不要做任何的RDB或者AOF操作。
如果对数据做持久化,建议将两者都打开。RDB在重启恢复时较快但是可能丢失一个备份时间内的所有数据;AOF丢失数据较少,但是其文件冗余导致体积较大。
AOF与RDB使用总结
1、redis在恢复时,优先使用AOF(存在且未损坏)
2、AOF 文件大小相较上次重写增大多少或者手动执行时,将触发重写,重写将内存中当前数据,都类似SET(插入)的方式,覆盖原来文件,文件大小大幅降低;
3、当新增节点时,使用的RBD先同步,然后期间的新增变更写命令流水,发送给新节点,保持后续数据一致Redis集群
集群元数据管理
Redis主从模式(无高可用)
Master-Slave模式,主写从读,单一Master多Slave,Master和Slave持有的数据完全相同。
哨兵模式(有高可用,不节省内存)
是对主从模式的改进,是Redis高可用性解决方案:由一个或多个Sentinel 实例 组成的Sentinel 系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器。
哨兵根据配置的Master信息,建立两条到Master的通讯链路:
- 一条连接用来订阅master的_sentinel_:hello频道与获取其他监控该master的哨兵节点信息;–同步自己信息通道
- 另一条连接定期向master发送INFO等命令获取master本身的信息;–获取集群信息通道
通过这两条通道,在建立后执行动作: - 定期向master发送INFO命令,获取集群信息;
- 定期向master个slave的_sentinel_:hello频道发送自己的信息;
- 定期向Master和Slave发送PING命令监控这些数据库和节点有没有停止服务;
如果被ping的数据库或者节点超时未回复,哨兵认为其主观下线。如果下线的是master,哨兵会向其他哨兵点发送命令询问他们是否也认为该master主观下线,如果达到一定数目(即配置文件中的quorum)投票,哨兵会认为该master已经客观下线,并选举领头的哨兵节点对主从系统发起故障恢复。
当确认Master下线后,将通过Raft算法选出领头哨兵:谁先发现Master下线谁将被提议成功,若一次不成功,则随机等待后提议自己,最先提议的将被选择成功。
领头哨兵选择出来后使用以下优先级选择新Master:优先级>复制偏移量>id最小
Redis Cluster集群分区模式(有高可用,节省内存)
在哨兵模式下,基本上能实现高可用和读写分离,但是这种模式下所有机器存储的数据完全相同,很浪费内存,所以将Redis改进为分布式存储,每个节点基本上数据不重复。
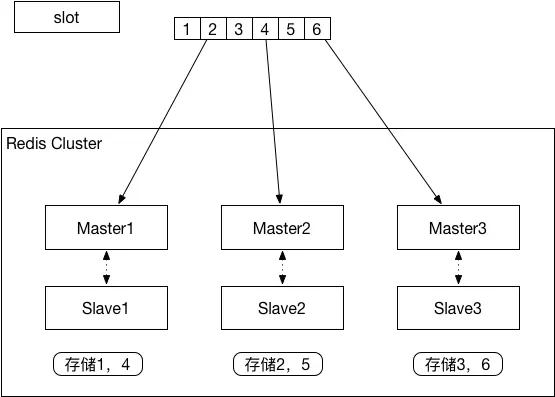
如上图所示,每个工作节点是一个单独的Master,为了提高节点的高可用,节点内部也是一个哨兵模式结构。
在操作数据时,客户端先根据key CRC算法后对槽[哈希槽](slot,长度16384)取模,然后根据node与Master节点的对应关系,查找到具体负责的Master节点。Master根据自己维护的位序列校验确实是自己负责的槽,那么就提供服务。
使用了一致性 Hash算法,CRC16校验后对16384取模来决定放置哪个槽,这些值按照顺序在环上排列,这样节点数目发生改变时,尽可能少的数据迁移,减少数据变动量和对资源的占用,将影响降到最低。
在客户端会缓存node-slot信息,而所有master节点在 Redis Cluster中的实现时,都存有所有的路由信息。当客户端的key 经过hash运算,发送slot 槽位不在本节点的时候:
- (1)如果是非集群方式连接,则直接报告错误给client,告诉它应该访问集群中那个IP的master主机。
- (2)如果是集群方式连接,则将客户端重定向到正确的节点上。
Redis数据同步
Slave刚启动阶段(全量复制)
- slave第一次启动时,连接Master,发送PSYNC命令,格式为<psync {runId} {offset}>,其中<psync ? -1>代表第一次全量同步;
- Master接下发现为第一次同步,Mater先回复自己的+fullresync {runId} {offset};
- Master执行bgsave命令来生产RDB文件,并将此后的所有写命令写入复制缓冲区中暂存起来;
- Master发送RDB文件,在文件发送完成后,发送到目前为止复制缓冲区中所有的操作命令。
– – 注意同步时间设置,防止复制超时,同时要注意复制缓冲区的大小设置,防止数据溢出。
异常恢复阶段(增量复制)
- 从节点发送<psync {runId} {offset}>;
- Master校验runId看是不是自身的Slave节点;
- 校验通过后查看offset是否在复制缓冲区中,若存在则直接同步,否则进行全量同步。
Redis扩容与缩减
Cluster集群中扩容与缩减主要是Master发生变更时,MasterA到MasterB部分槽所在节点的变更;– –整个过程类似ConnCurrentHashMap打标。
槽迁移的过程中有一个不稳定状态,这个不稳定状态会有一些规则,这些规则定义客户端的行为,从而使得Redis Cluster不必宕机的情况下可以执行槽的迁移。
假设这批待迁移的槽编号为1、2、3,并假设左边的节点为MasterA节点,右边的节点为MasterB节点。(集群不能自动迁移,需要手动或者通过工具触发迁移)
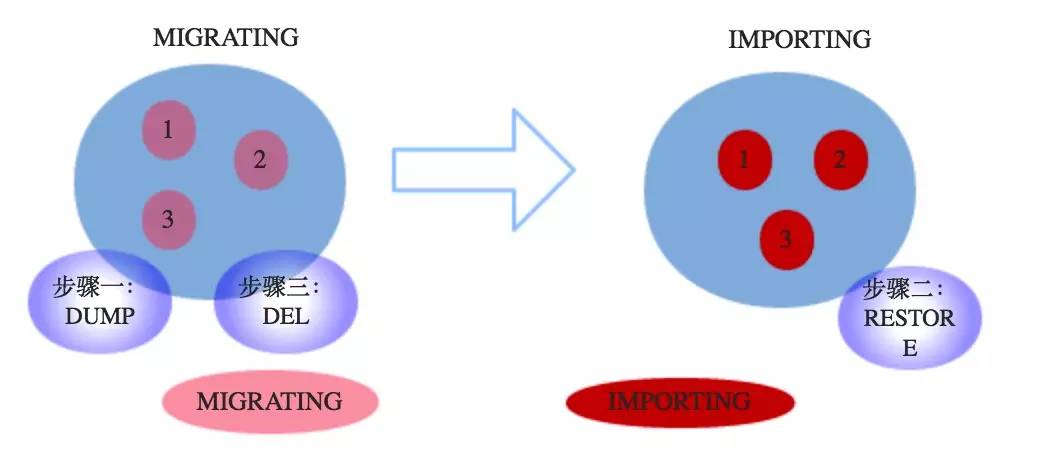
MIGRATING状态
本例中MIGRATING状态是发生在MasterA节点中的一种槽的状态,预备迁移槽的时候槽的状态首先会变为MIGRATING状态,这种状态的槽会实际产生什么影响呢?
当客户端请求的某个Key所属的槽正处于MIGRATING状态的时候,影响有下面几条:
- 如果Key存在则正常成功处理;
- 如果Key不存在,则返回客户端ASK,仅当这次请求会转向另一个节点,并不会刷新客户端中node的映射关系,也就是说下次该客户端请求该Key的时候,还会选择MasterA节点;
- 如果Key包含多个命令,如果都存在则成功处理,如果都不存在,则返回客户端ASK,如果一部分存在,则返回客户端TRYAGAIN,通知客户端稍后重试,这样当所有的Key都迁移完毕的时候客户端重试请求的时候回得到ASK,然后经过一次重定向就可以获取这批键;
IMPORTING状态
本例中的IMPORTING状态是发生在MasterB节点中的一种槽的状态,预备将槽从MasterA节点迁移到MasterB节点的时候,槽的状态会首先变为IMPORTING。IMPORTING状态的槽对客户端的行为有下面一些影响:
- 提前过来的正常命令会被MOVED重定向;如果是ASKING命令(MasterA返回给客户端的Ask)则命令会被执行,从而Key没有在老的节点已经被迁移到新的节点的情况可以被顺利处理;
- 如果Key不存在则新建(新建在Master A?);
- 没有ASKING的请求和正常请求一样被MOVED,这保证客户端node映射关系出错的情况下不会发生写错;