数据结构
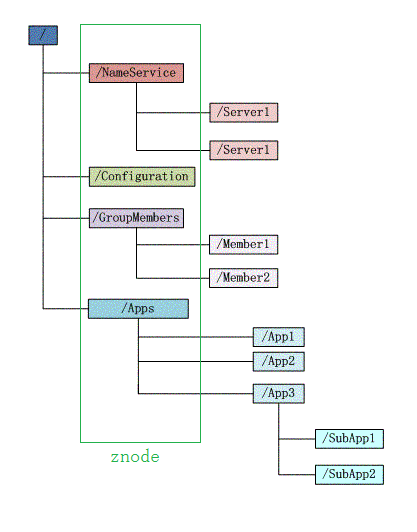
1、znode的路径唯一标识,每个znode可以存储数据,且数据可以有多个版本;
2、znode可以是临时节点,一旦创建这个znode的客户端与服务器失去联系,这个znode也将自动删除;
3、ZooKeeper的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态成为session。
4、znode可以被监控,包括这个目录节点中存储的数据被修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是ZooKeeper的核心特性。
为什么在kafka中controller和broker都是使用临时节点来表示? 这是因为,当节点出现宕机时,需要允许集群做出响应,通过临时节点的回调进行对应集群协调处理。
使用场景
Zookeeper是一个高效的分布式协调服务,可以提供配置信息管理、命名、分布式同步、分布式锁、集群管理、数据库切换等服务。它不适合用来存储大量信息,可以用来存储一些配置、发布与订阅等少量信息。
集群
集群:貌似只能一个leader,多个follower
首先要注意的Zab和Paxos算法的区别 。
- Paxos算法:用于构建一个分布式一致性状态系统,保证系统数据的一致性。
- Zab算法:则主要用于构建一个高可用的分布式主备系统。
集群数量为奇数(2N+1)原因:一个ZooKeeper集群如果要对外提供可用的服务,那么集群中必须要有过半的机器正常工作并且彼此之间能够正常通信。对于5台和6台来说,都必须至少3台机器存活,所以为了节约资源,一般选择5台即可;
集群读写
写请求只能在leader进行,客户端连接到任意节点后,若为写请求,则follower将写请求转发给Leader节点。– 转发会不会造成Leader资源紧张??
任意节点可以提供读请求。
集群脑裂
集群的脑裂通常是发生在节点之间通信不可达的情况下,集群会分裂成不同的小集群,小集群各自选出自己的master节点,导致原有的集群出现多个master节点的情况,这就是脑裂。
怎么防止
ZooKeeper默认采用了Quorums(法定人数)这种方式,即指定集群中选举leader所需的最少节点数(新集群存活数必须为原集群的一半)才能选举出Leader。
在节点数量是奇数个的情况下, zookeeper集群总能对外提供服务(即使损失了一部分节点);如果节点数量是偶数个,会存在zookeeper集群不能用。
Zab协议
Zookeeper角色与状态:
- 角色:leader,follower,observer
- 状态:leading,following,observing,looking
follower和observer都负责处理客户端的读请求,写转发至leader节点以及同步leader的广播数据、状态,但是observer不会参与数据确认和选举的投票。ZXID
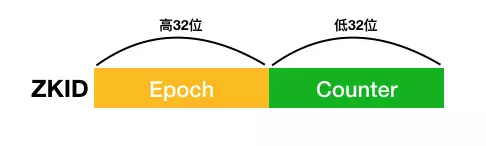
ZooKeeper会为每一个事务生成一个唯一且递增长度为64位的ZXID,ZXID由两部分组成:低32位表示计数器(counter)和高32位的纪元号(epoch)。epoch为当前leader在成为leader的时候生成的,且保证会比前一个leader的epoch大,在其为Leader期间,Epoch保持不变。
ZXID结构示意图如下:
集群恢复
Zab协议的设计参考了Paxos协议,在广播阶段为保证节点事务一致性采用了两阶段提交方式。
恢复阶段
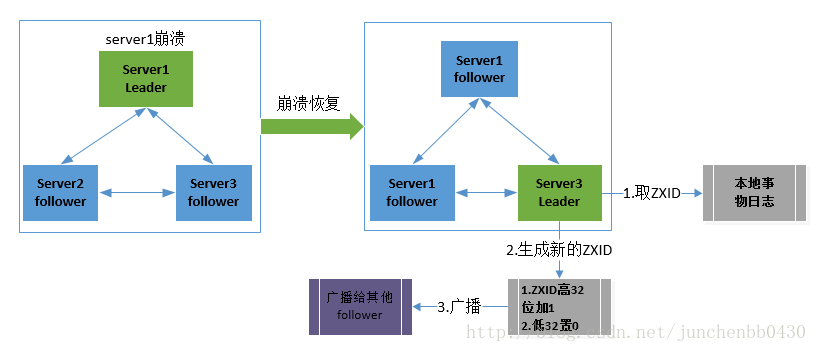
当集群启动或Leader崩溃后,进入该阶段。大致分为4步:
- 选举: 当leader崩溃后,集群进入选举阶段,开始选举出潜在的新leader(一般为集群中拥有最大ZXID的节点);
- 进入发现阶段,follower与潜在的新leader进行沟通,如果发现超过法定人数的follower同意,则潜在的新leader将epoch加1,进入新的纪元,新的leader产生;
- 集群间进行数据同步,保证集群中各个节点的事务一致;
- 集群恢复到广播模式,开始接受客户端的写请求;
考虑leader将commit消息提交到本地队列之前和之后两种情况,新选举出来的Leader必须是“干净的”,即不含未提交的proposal,且拥有最高的ZXID,也即数据最新。
当epoch和zxid都相等时,选择server id最大的(就是我们配置zoo.cfg中的myid);
广播阶段
也即对外服务阶段。
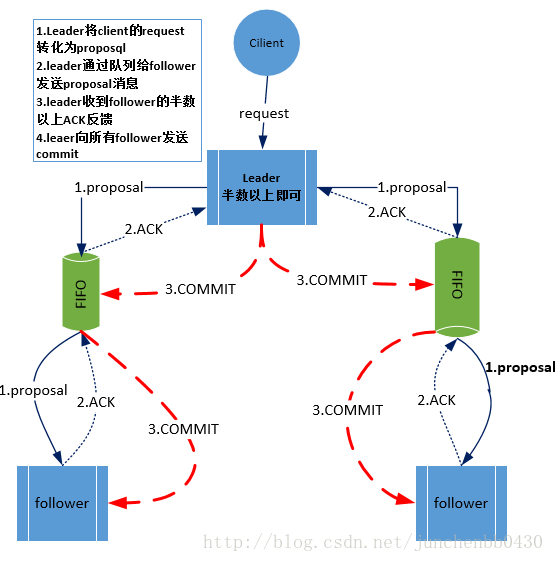
- leader从客户端收到一个写请求;
- leader生成一个新的事务并为这个事务生成一个唯一的ZXID;
- leader将这个事务通过proposal发送给所有的follows节点(Leader对每个follower节点都维护了一个本地队列);
- follower节点将收到的事务请求加入到历史队列(history queue)中,并发送ack给ack给leader;
- 当leader收到大多数follower(超过法定数量)的ack消息,则在发送commit消息给follows,且会发送INFORM消息给所有Observer(成不成功不影响提交服务);
- 当follower收到commit请求时,会判断该事务的ZXID是不是比历史队列中的任何事务的ZXID都大,如果是则提交,如果不是则等待比它更小的事务的commit,若能被消费,则将操作写入本地事物日志中。
Zookeeper在全局上保证了数据的有序性,整个过程做类似2PC提交。
只有Leader才能处理事务(写)请求,当Follower接收到事务请求后,会转发给Leader节点。
集群扩容
目前Zookeeper的水平扩容必须逐台或则集群重启,更新配置后再次启动。
Observer
Observer是一个类Follower节点,但是其不参与任何阶段的投票,其可以有以下两个作用:
- 作为读节点。Observer不参与投票确认,所以其增减对整个集群的结构没影响,但是因为也能接收客户端的读写请求并将写请求转发给Leader节点,所以Observer很适合在有限影响集群性能的情况下提供读服务。
- 作为数据中心:Observer的数据来自于Leader在commit成功后的INFORM消息,所以可以作为一个单独的数据中心(备份)对外服务,很适合用于做异地数据中心;