MHA
在 MySQL 故障切换过程中,MHA 能做到在 0~30 秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA 能在最大程度上保证数据的一致性。
MHA Manager(管理节点)
MHA Manager 可以单独部署在一台独立的机器上管理多个 master/slave 集群,也可以部署在一台 slave 节点上;
MHA Node(数据节点)
MHA Node 运行在每台 MySQL 服务器上,MHA Manager 会定时探测集群中的 master 节点,当 master 出现故障时,它可以自动将拥有最新数据的 slave 提升为新的 master,然后将所有其他的 slave 重新指向新的 master。
工作流程
1、从宕机崩溃的 master 节点保存二进制日志事件(binlog events),当不成功时识别含有最新更新数据的 slave
2、应用差异的中继日志(relay log)到其他slave –> 保证从属服务器节点之间的数据是同步的
3、根据保存了最新二进制日志节点中,提升一个 slave 为新 master
4、使用其他的 slave 连接新的 master 进行复制。
write-ahead log
引入原因
在操作系统中,都是以页为单位来进行管理存储空间的,任何增删改操作最终都会操作完整的一个页,会将整个页加载到buffer poll中,然后进行修改,修改完后不会立即刷新到磁盘,因为刷新是一个随机IO,仅仅修改了一条数据就刷新数据页过于浪费,但是不刷新又会造成存在可能得系统崩溃内存数据丢失。
为了提高效率,将变化的部分用一个性能较高的顺序存储文件来记录所有的变动日志,也即write-ahead log(WAL)记录了哪个页,多少偏移量,什么数据发生了变更。
文件操作模型
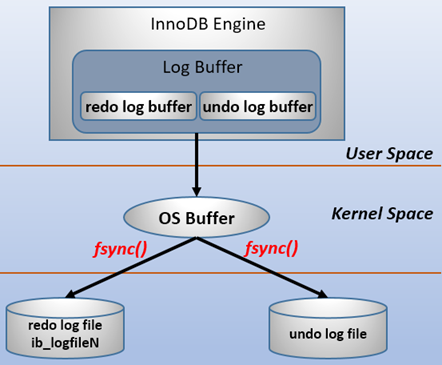
刷新方式
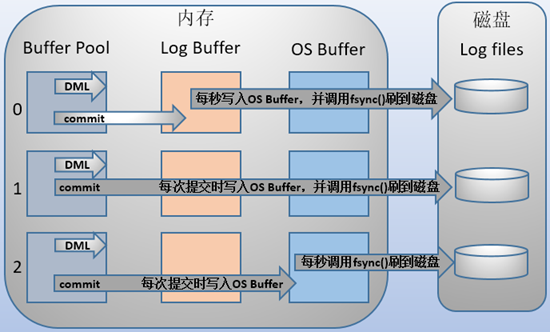
innodb_flush_log_at_trx_commit的值来决定日志产生commit动作后怎么刷新到磁盘上去,值为0、1、2,其中1为默认方式。
MTR(Mini-Transaction)
一个事务中,可能存在多个数据块内的操作,也可能会涉及到更新聚簇索引和二级索引,那么就会产生多个redo log,如何保证整个过程中的日志原子性的呢。
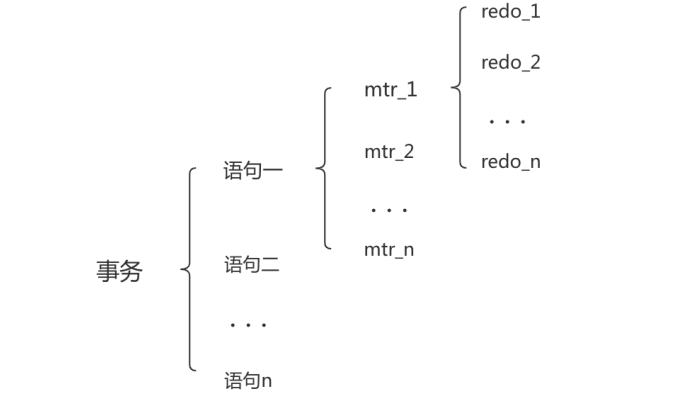 对底层页面进行一次原子操作的过程被称为MTR,其生成的日志,都被mysql放到了大小为512字节的页中,当MTR结束后,将产生的一组redo log日志写到redo buffer中,然后按照刷新策略,立即整体刷新到磁盘中。
对底层页面进行一次原子操作的过程被称为MTR,其生成的日志,都被mysql放到了大小为512字节的页中,当MTR结束后,将产生的一组redo log日志写到redo buffer中,然后按照刷新策略,立即整体刷新到磁盘中。
典型场景及变体:mysql redo log; redis aof; kafka本身 ;业务开发中的常见行为:对于耗时较高的行为,先写一条数据库记录,表示这个任务将被执行,之后再异步进行实际的任务执行;
操作日志过程
一个事务的事务型操作过程归纳为下列步骤:
- 索引打标上排它锁(事务型操作);
- 将原数据入log buffer进行备份;
- copy原数据到undo log文件中,方便事务进行构建回滚点;
- 操作变更业务字段值,DB_TRX_ID,回滚指针到undo log中地址;
- 在事务操作时,检测到存在排它锁,进入事务挂起等待阶段,等前面的事务提交后才继续执行。RR下为了防止对同一条数据变更出现可重复读并发变更,需要再变更前使用select ... for update进行排它锁定 -- --> 一锁二查三变更
- 提交事务,log buffer刷入redo log文件中。
操作日志
binlog
引擎层会记录redolog,服务层会记录binlog。redo log是物理日志,记录的是“在XXX数据页上做了XXX修改”;binlog是逻辑日志,记录的是原始逻辑,其记录是对应的SQL语句;binlog 是追加写入的,就是说 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志;
redo log–机器
redo log是InnoDB存储引擎层的日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,数据修改之后的值,不管事务是否提交都会记录下来。如果数据库掉电,InnoDB存储引擎会使用redo log恢复到掉电前的时刻,以此来保证数据的完整性。当客户端执行每条事务SQL时,更新记录会被首先写入log buffer;当客户端执行COMMIT命令时,log buffer中的内容会被视情况刷新到磁盘。redo log在磁盘上作为一个独立的文件存在,是循环写入的。
undo log–事务
与redo log相反,undo log是为回滚而用,undo log一般是逻辑日志,根据每行记录进行记录,其不会落具体文件。
此处只通过RR隔离级别下的一个例子讲解undo日志怎么变更。
1
2
3
4
5
6
7
8
9
10
11
create index test_idx on test(comment);
insert into test values(1, ‘aaa’);
insert into test values(2, ‘bbb’);
-- update primary key
update test set id = 9 where id = 1; --- 语句1
-- update non-primary key with different value
update test set comment = ‘ccc’ where id = 9; --- 语句2
-- 初始时DB_TRX_ID事务id为1809,当前事务id为1811
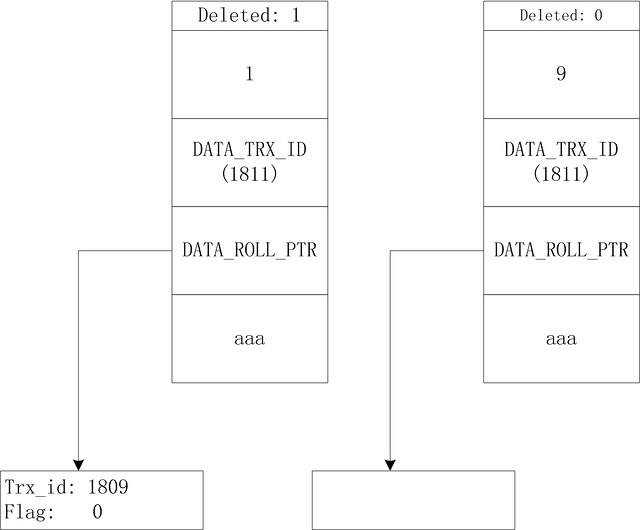
语句1处:主键的变更对InnoDB来说其实是删除原数据并插入一条新数据,所以在索引上加锁后,原数据删除标志位DELETE_BIT变更为0,并且回滚指针指向了undo log中记录的变更前的原始数据并变更事务版本号。同时,在索引上添加一条记录,该记录回滚指向为空。
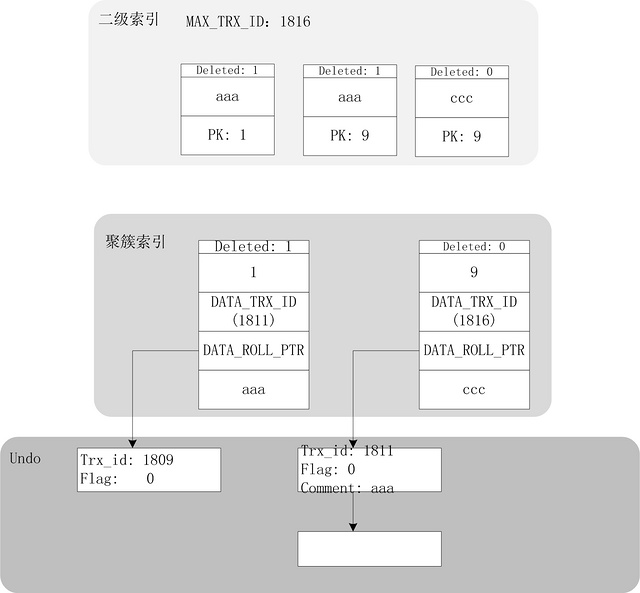
语句2处:此阶段和前面没有什么不同,只是需要将二级索引进行重构,将comment=’ccc’添加进去,同时,在undo long中,回滚的原始数据添加到回滚链中去。
有一个点需要注意,undo log记录了所有事务操作数据的回滚点,同一条数据变更(即DB_ROW_ID相同)在同一个(链表)链路中
一条更新语句执行的顺序
update T set c=c+1 where ID=2;
- 执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
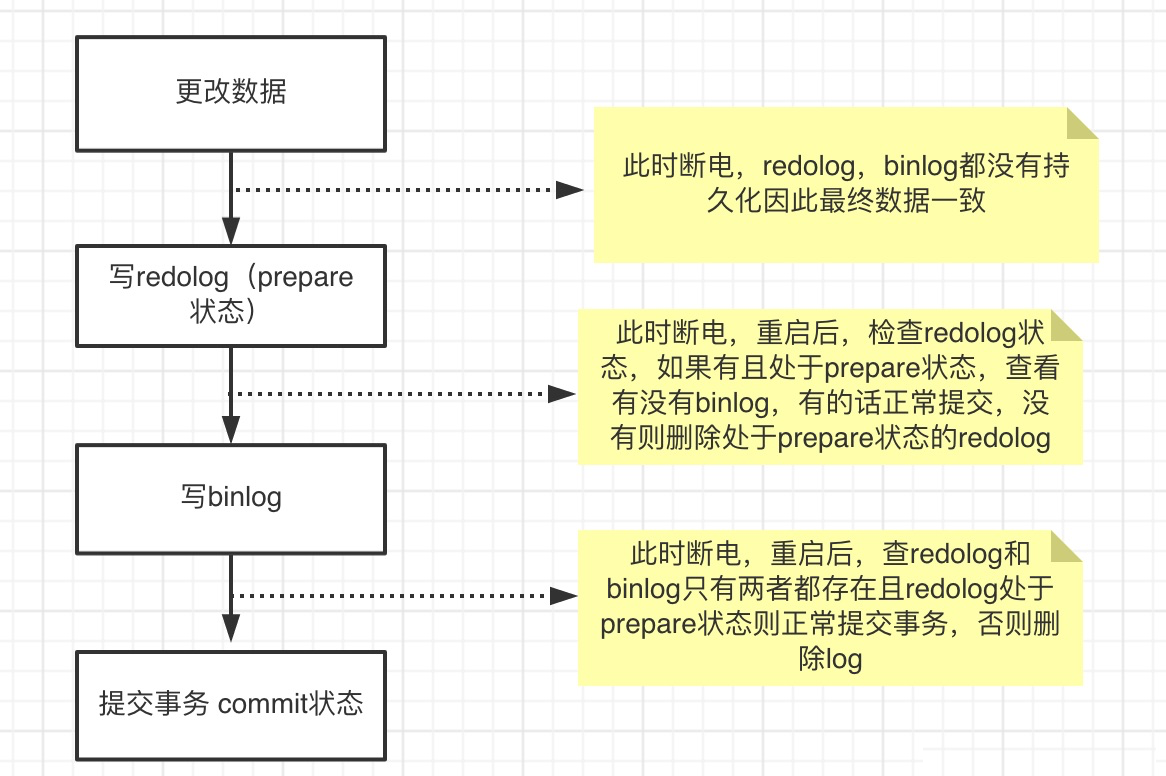
- 引擎将这行新数据更新到内存中,在Buffer Pool中标记页为脏页(dirty page),同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- MVCC下构建undo链路、即:生成undo log用于MVCC回滚。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。 redo log(旧数据变更先打标、后剔除)两个状态“相当于二阶段事务”管控。