事务管理,异步解耦,削峰填谷,数据同步等应用场景

1、NameServer 之间互不通信,无法感知对方的存在。
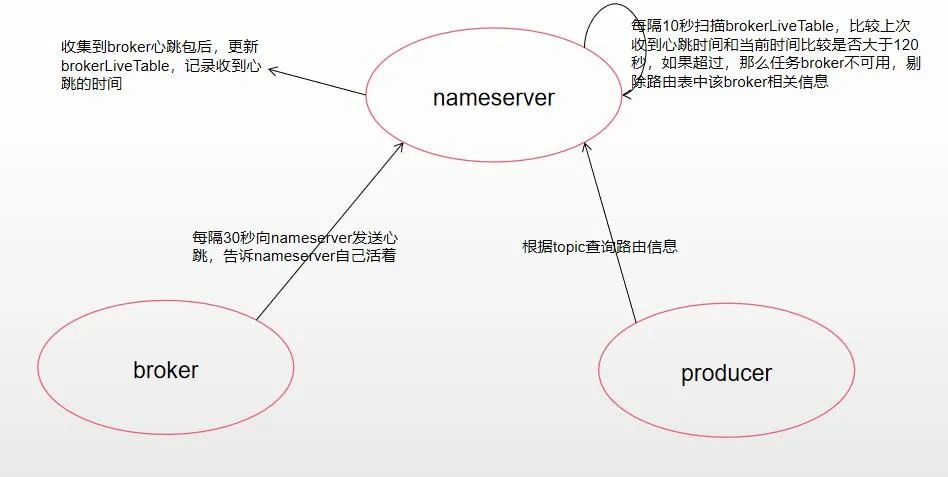
2、Broker 服务会与每台 NameServer 保持长连接,每30s向 NameServer 发送心跳包。
3、生产者&消费者与 NameServer 集群中的一台服务器建立长连接,并持有整个 NameServer 集群的列表,且定期去拉取主题的路由信息。
4、rocketMq通过自身的NameServer进行协调,当一个broker挂了,会把当前请求迁移到其他Broker上去,而不是slave升级为Master。
所以都不会立即感知到变更;
发送的消息中已经携带了QueueId,标识当前消息会被放到哪个ConsumeQueue中。
NameServer
 路由发现不是实时的,路由变化后,NameServer不主动推给客户端,等待producer定期拉取最新路由信息。当路由发生变化时通过在消息发送端的容错机制来保证消息发送的高可用。
路由发现不是实时的,路由变化后,NameServer不主动推给客户端,等待producer定期拉取最新路由信息。当路由发生变化时通过在消息发送端的容错机制来保证消息发送的高可用。
多个NameServer服务器之间不进行通信,这样路由信息发生变化时,各个NameServer服务器之间数据可能不是完全相同的,也是通过发送端的容错机制保证消息发送的高可用。
NameServer每隔10s扫描BrokerLiveTable,连续120s没收到心跳包,则移除该Broker并关闭socket连接,broker正常下线也会触发路由剔除;
Controller模式
Controller单独部署或者内嵌在NameServer下,Broker 通过与 Controller 的交互完成 Master 的选举支持主从的自动主从切换。
Controller会监听每个 Broker 的连接通道,当Broker发生变动后,就会判断该 Broker 是否为 Master,如果是,则会触发选主的流程。选举 Master 的⽅式⽐较简单,我们只需要在该组 Broker 所对应的 SyncStateSet 列表中,挑选⼀个出来成为新的 Master 即可,并通过 DLedger 共识后应⽤到内存元数据,最后将结果通知对应的Broker副本组。
DLedger 部署在每个Broker节点中,通过Raft协议去投票产生新的Master节点。阅读参考
Rebalance
触发Rebalance的根本因素无非是两个:参阅
- 订阅Topic的队列数量变化;
- 消费者组信息变化。
典型触发场景:
- 队列信息变化:
- broker宕机等变更
- 队列扩容/缩容
- broker升级等运维操作
- 消费者组信息变化:
- 日常发布过程中的停止与启动
- 消费者异常宕机
- 网络异常导致消费者与Broker断开连接
- 主动进行消费者数量扩容/缩容
- Topic订阅信息发生变化
队列信息和消费者组信息这些都维护在Broker中,当发生变更时,以某种通知机制告诉消费者组下所有实例,需要进行Rebalance,Borker充当着协调者的角色。Rebalance也是以消费组纬度进行的。
生产方动作
Producer会定期检测RocketMQ集群的状态,包括Broker的变化和消费者组的变化。当发现消费者组发生变化或者Broker发生变化时,Producer会触发rebalance。
消费方动作
Broker是通知每个消费者各自Rebalance,即每个消费者自己给自己重新分配队列,而不是Broker将分配好的结果告知Consumer。
与kafka的异同
RocketMQ与Kafka Rebalance机制类似,二者Rebalance分配都是在客户端进行,不同的是
- Kafka:会在消费者组的多个消费者实例中,选出一个作为Group Leader,由这个Group Leader来进行分区分配,分配结果通过Cordinator(特殊角色的broker)同步给其他消费者。相当于Kafka的分区分配只有一个大脑,就是Group Leader。
- RocketMQ:每个消费者,自己负责给自己分配队列,相当于每个消费者都是一个大脑。
消息存储文件设计
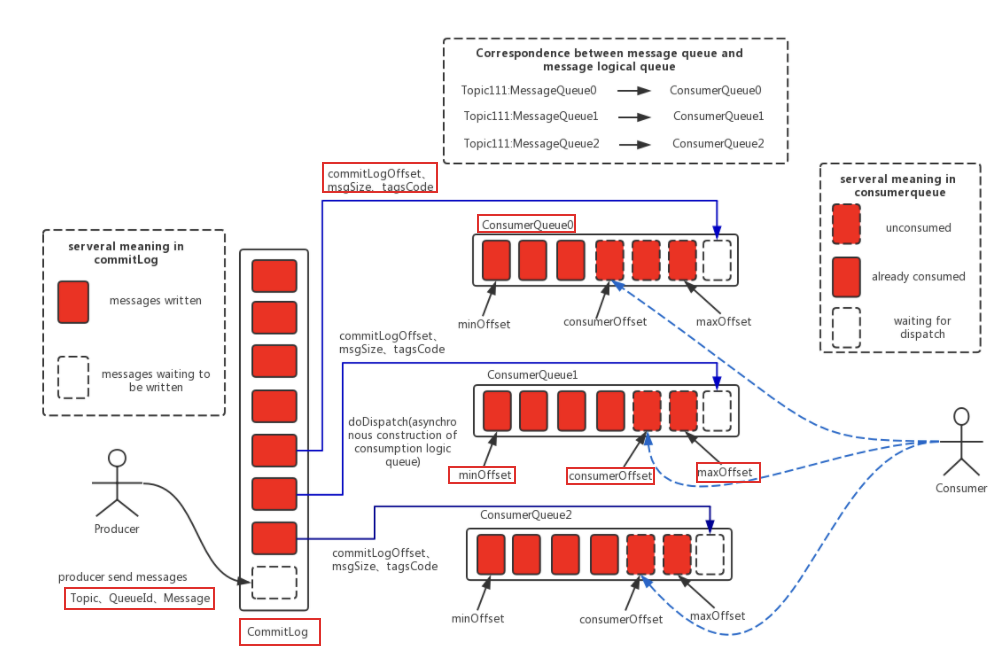
消息存储主要体现在三个文件中:CommitLog(真正存储消息体的地方)、ConsumeQueue(某个Topic下某个Queue的消息索引信息)、IndexFile(通过key或时间区间来查询消息的索引文件)。
全图:
 简图:
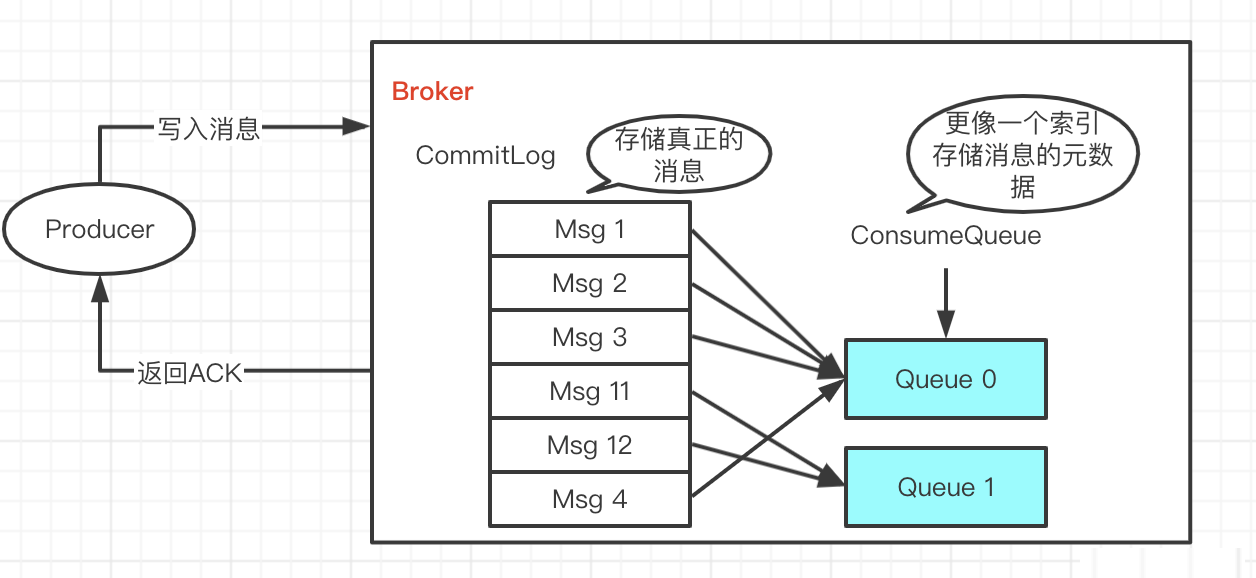
简图:
 细图:
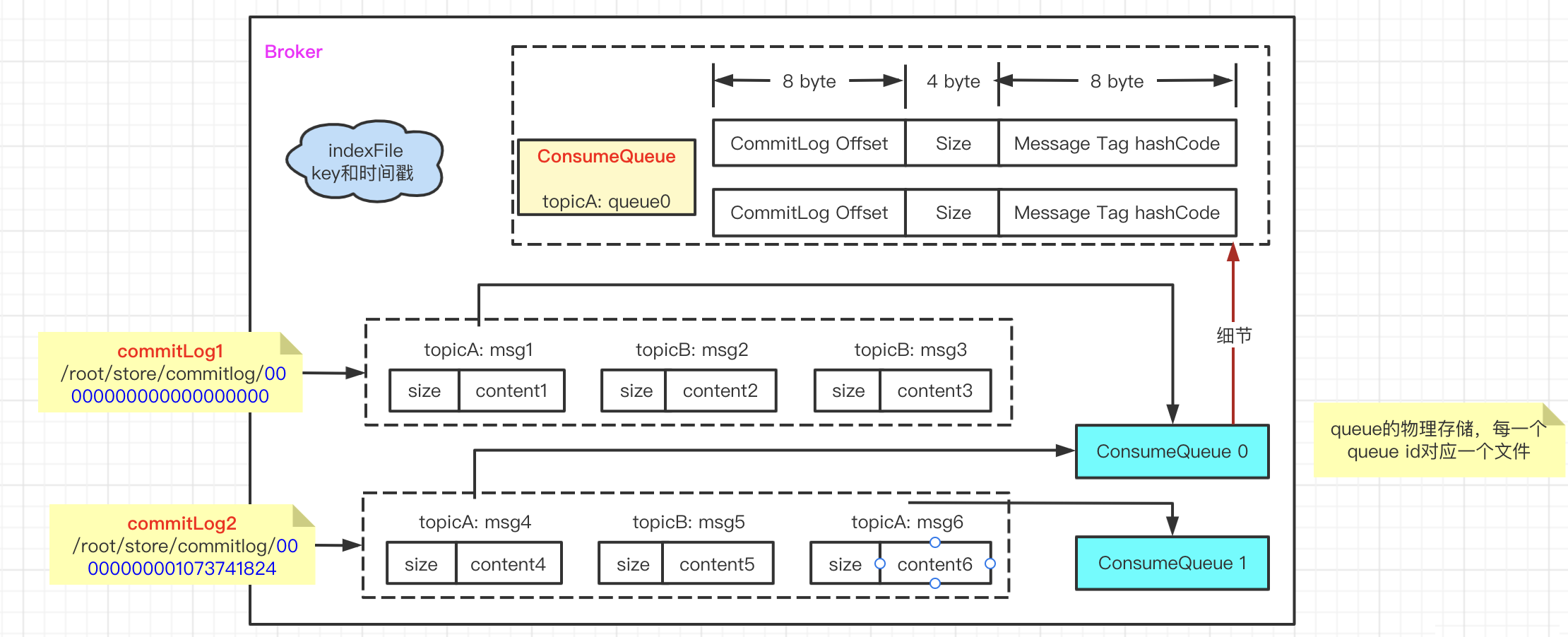
细图:
文件处理
CommitLog 文件
真正存储消息内容的地方,一个Broker中,所有的topic消息都混在在一起的。
消息随着到达 Broker 的顺序写入 CommitLog 文件,每个文件默认为1G,文件的命名和kafka一样,使用该存储在消息文件中的第一个全局偏移量来命名文件。
producer发送消息后,消息先保存到commitLog,然后重投递线程会扫描是否有新消息被保存到 CommitLog,如果有则将这条消息查出来,执行重投递逻辑,构建该消息的索引(包括 ConsumeQueue 和 IndexFile)。
ConsumeQueue 文件

可以把 ConsumeQueue 看作是索引项组成的数组,根据QueueId进行追加。
也可以看出,消息在全局上不是有序的。
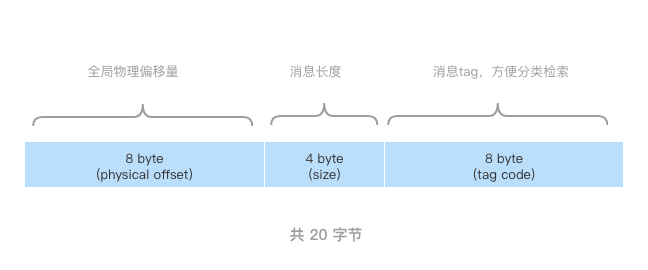 通过存入节点固定大小,能使用访问类似数组下标的方式来快速定位条目。
通过存入节点固定大小,能使用访问类似数组下标的方式来快速定位条目。
IndexFile 文件
IndexFile文件主要是服务于通过Key进行消息查询的功能。
消息消费
客户端发起消息消费请求,请求码为RequestCode.PULL_MESSAGE,对应的处理类为PullMessageProcessor。
Broker 在收到客户端的请求之后,会根据topic和queueId、消息消费进度(ConsumeQueue 逻辑偏移量),通过逻辑偏移量logicOffset* 20可以快速定位到在哪个ConsumeQueue的哪个起始位置,然后读取20个字节即得到了一个条目。
Pull模式下,PullMessageService 拉取完一批消息后,将消息提交到线程池后会“马不蹄停”去拉下一批消息,如果此时消息消费线程池处理速度很慢,处理队列中的消息会越积越多。
消息积压
消费端的限流机制:
- 消息堆积数量控制:当消息消费处理队列中的消息条数超过1000条会触发消费端的流控,其具体做法是放弃本次拉取动作,并且延迟50ms后将放入该拉取任务放入到pullRequestQueue中,每1000次流控会打印一次消费端流控日志。
- 消息堆积大小:处理队列中堆积的消息总内存大小超过100M,同样触发一次流控。
通过调整发送方速率、调整分区数提高并行处理能力、监控和告警、压力测试、定期审查、容量规划、消费端异常处理等手段去规避积压。
文件清理
broker 文件清理主要是清理commitlog , ConsumeQueue , indexFile。RocketMQ默认是清理72小时之前的消息, 默认是凌晨4点触发清理, 除非磁盘空间占用到75% 以上了。
RocketMQ拿到所有的MappedFile(抛去现在正在使用的)比对每个MappedFile的最后一条消息的时间,如果是72小时之前的就把MappedFile对应的文件删除了,销毁对应MappedFile,这种情况的话只要你MappedFile 最后一条消息还在存活实效内的话,它就不会清理这个MappedFile。
清理完成commitlog 之后,就会拿到commitlog中最小的offset ,然后去ConsumeQueue与indexFile中把小于offset 的记录删除掉。