搜索类型
- 结构化检索
也称作行数据,是由二维表结构来逻辑表达和实现的数据,具有固定格式或有限长度的数据,如数据库,元数据等。 - 非结构化检索
又可称为全文数据,不定长或无固定格式,不适于由数据库二维表来表现,包括所有格式的办公文档、XML、HTML、Word 文档。- 顺序扫描:顾名思义,就和我们人眼查看一样,从头一个个查找。
- 全文检索:将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索。
全文检索
Solr 和 Elasticsearch 都是比较成熟的全文搜索引擎,能完成的功能和性能也基本一样。Solr 和 Elasticsearch 都是比较成熟的全文搜索引擎,能完成的功能和性能也基本一样,两者底层都是依赖于 Lucene。 ES 本身就具有分布式的特性和易安装使用的特点,而 Solr 的分布式需要借助第三方来实现,例如通过使用 ZooKeeper 来达到分布式协调管理。
倒排索引
如何理解倒排索引呢? 假如现有三份数据文档,文档的内容如下分别是:
1
2
3
* Java is the best programming language. //Doc_1
* PHP is the best programming language. //Doc_2
* Javascript is the best programming language. //Doc_3
为了创建倒排索引,我们通过分词器将每个文档的内容域拆分成单独的词(我们称它为词条或 Term),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。
结果如下所示:
1
2
3
4
5
6
7
8
9
10
11
Term Doc_1 Doc_2 Doc_3
-------------------------------------
Java | X | |
is | X | X | X
the | X | X | X
best | X | X | X
programming | x | X | X
language | X | X | X
PHP | | X |
Javascript | | | X
-------------------------------------
这种由属性值来确定记录的位置的结构就是倒排索引。带有倒排索引的文件我们称为倒排文件。上面的内容转换倒排索引的结构如下图所示:
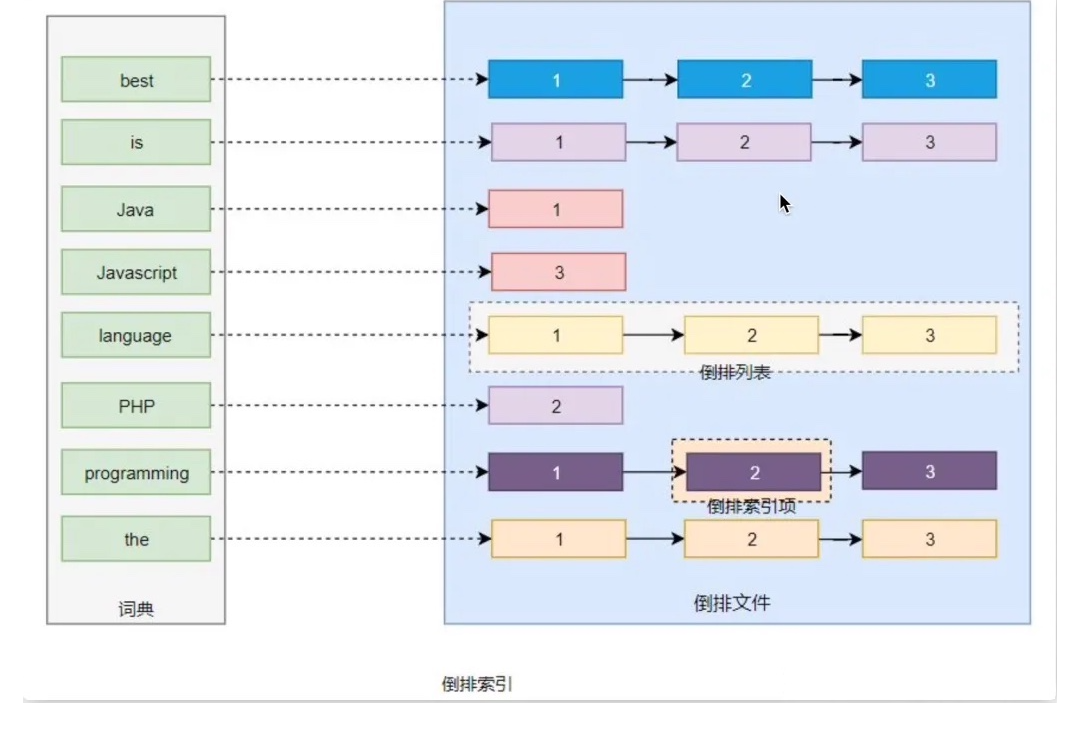 核心术语:
核心术语:
- 词条(Term): 索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说一般指分词后的一个词。
- 词典(Term Dictionary): 或字典,是词条 Term 的集合。单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
- 倒排表(Post list):倒排表记录的是某个词在哪些文档里出现过以及出现的位置。倒排表记录的不单是文档编号,还存储了词频等信息。
- 倒排文件(Inverted File): 所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
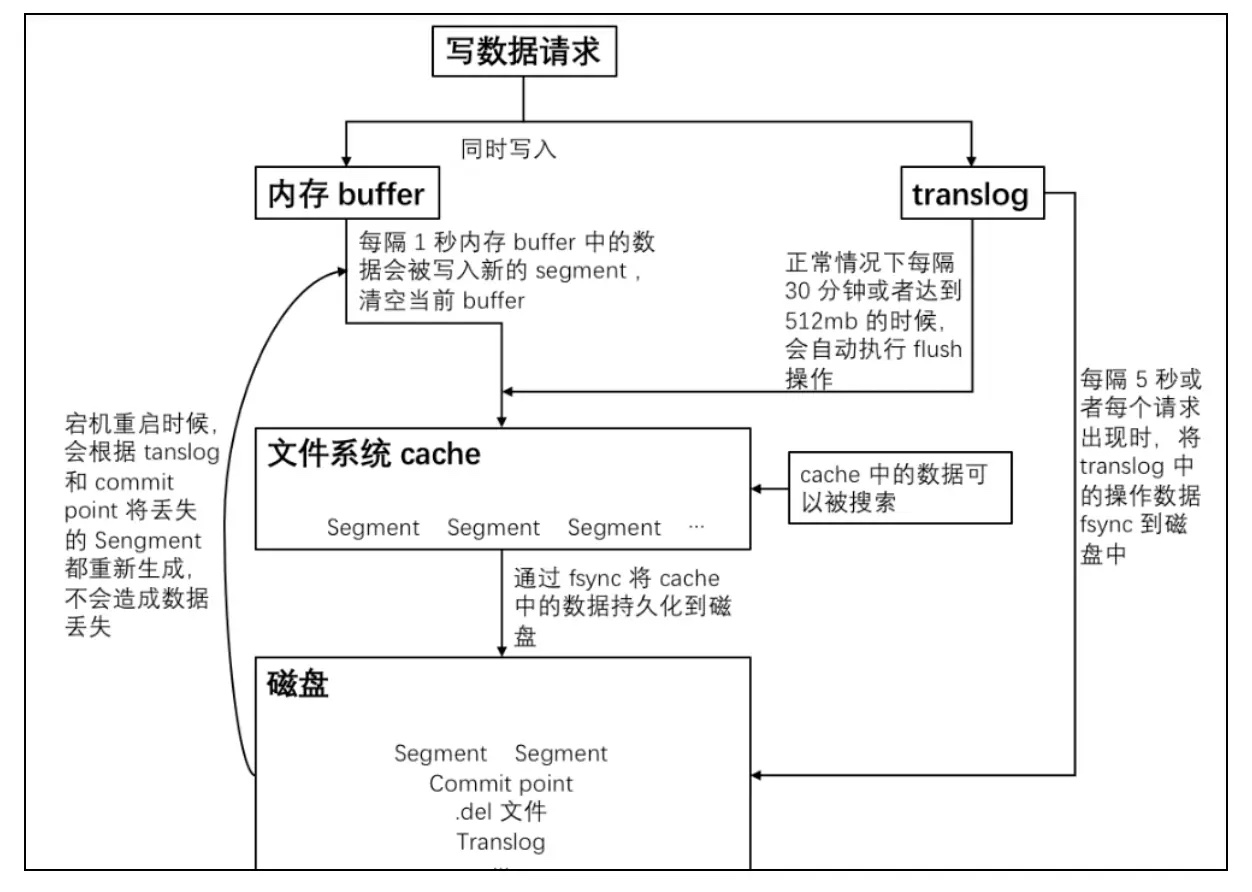
ES 核心概念
一个分布式的实时文档存储、分析、近实时的搜索引擎。
ES 的集群搭建很简单,不需要依赖第三方协调管理组件,自身内部就实现了集群的管理功能,每个节点(实例)配置相同的 cluster.name 即可加入集群,默认值为 “elasticsearch”。
选举
选举开始,先从各节点认为的 Master 中选,规则很简单,按照 ID 的字典序排序,取第一个(类似Raft算法?)。如果各节点都没有认为的 Master ,则从所有节点中选择,规则同上。
如果节点数达不到最小值的限制(discovery.zen.minimum_master_nodes),则循环上述过程,直到节点数足够可以开始选举。
当连接到Master节点数超过discovery.zen.minimum_master_nodes后,Master开始提供服务,为了防止出现脑裂,一般设置超过半数节点
发现机制
ES内置默认发现模块Zen Discovery 通过一个相同的设置 cluster.name 就能将不同的节点连接到同一个集群。其职责是发现集群中的节点以及选举 Master 节点。
发现模块通过配置的单播节点列表,连接到其中一个节点后,得到整个集群所有节点的状态,然后它会联系 Master 节点,并加入集群。
选主
每个节点既可以是候选主节点也可以是数据节点,通过在配置文件 ../config/elasticsearch.yml 中设置即可,默认都为 true。
1
2
node.master: true //是否候选主节点
node.data: true //是否数据节点
一个节点既可以是候选主节点也可以是数据节点,为了提高集群的健康性,应对集群中的节点做好角色上的划分和隔离。可以使用几个配置较低的机器群作为候选主节点群。
数据节点负责数据的存储和相关的操作,例如对数据进行增、删、改、查和聚合等操作,所以数据节点(Data 节点)对机器配置要求比较高,对 CPU、内存和 I/O 的消耗很大。
候选主节点可以被选举为主节点(Master 节点),集群中只有候选主节点才有选举权和被选举权,其他节点不参与选举的工作。
主节点负责创建索引、删除索引、跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点、追踪集群中节点的状态等,稳定的主节点对集群的健康是非常重要的。
主节点和其他节点之间通过 Ping 的方式互检查,主节点负责 Ping 所有其他节点,判断是否有节点已经挂掉。其他节点也通过 Ping 的方式判断主节点是否处于可用状态。
虽然对节点做了角色区分,但是用户的请求可以发往任何一个节点,并由该节点负责分发请求、收集结果等操作,而不需要主节点转发。
脑裂现象
“脑裂”问题可能有以下几个原因造成:
- 网络问题: 集群间的网络延迟导致一些节点访问不到 Master,认为 Master 挂掉了从而选举出新的 Master,并对 Master 上的分片和副本标红,分配新的主分片。
- 节点负载: 主节点的角色既为 Master 又为 Data,访问量较大时可能会导致 ES 停止响应(假死状态)造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。
- 内存回收: 主节点的角色既为 Master 又为 Data,当 Data 节点上的 ES 进程占用的内存较大,引发 JVM 的大规模内存回收,造成 ES 进程失去响应。
优化措施:
- 适当调大响应时间,减少误判
- 选举触发条件调整,配置文件中设置参数 discovery.zen.munimum_master_nodes 的值,需要参与选举的候选主节点的节点数,默认值是 1。
- 角色分离,候选主节点和数据节点进行角色分离。
分片(Shards)
ES 支持 PB 级全文搜索,当索引上的数据量太大的时候,ES 通过水平拆分的方式将一个索引上的数据拆分出来分配到不同的数据块上,拆分出来的数据库块称之为一个分片。
这类似于kafka存储结构。
在一个多分片的索引中写入数据时,通过路由来确定具体写入哪一个分片中,所以在创建索引的时候需要指定分片的数量,并且分片的数量一旦确定就不能修改。默认为一个索引创建 5 个主分片, 并分别为每个分片创建一个副本。
1
2
3
4
5
6
7
PUT /myIndex
{
"settings" : {
"number_of_shards" : 5,
"number_of_replicas" : 1
}
}
假如3 个节点的集群,共拥有 12 个分片,其中有 4 个主分片(S0、S1、S2、S3)和 8 个副本分片(R0、R1、R2、R3),每个主分片对应两个副本分片,节点 1 是主节点(Master 节点)负责整个集群的状态。
则分配结果如下:
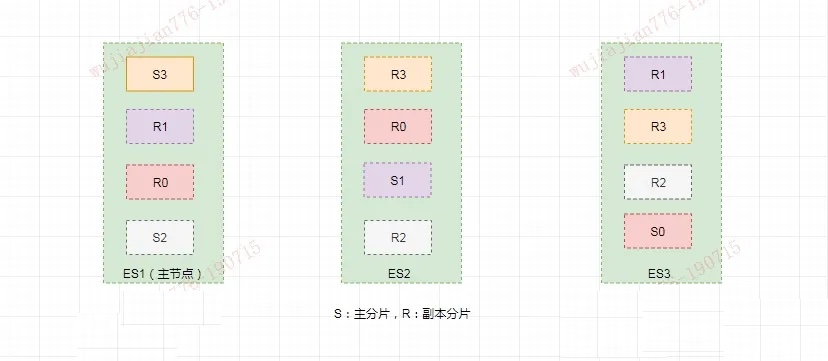
路由
看着和kafka真的很类似?
1
shard = hash(routing) % number_of_primary_shards
Routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。
在创建索引的时候就确定好主分片的数量并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
在 ES 集群中每个节点通过上面的计算公式都知道集群中的文档的存放位置,所以每个节点都有处理读写请求的能力。 在一个写请求被发送到某个节点后,该节点即为前面说过的协调节点,协调节点会根据路由公式计算出需要写到哪个分片上,再将请求**转发到该分片的主分片节点上**– 节点内部进行转发。
副本(Replicas)
主分片和对应的副本分片是不会在同一个节点上的,所以副本分片数的最大值是 N-1(其中 N 为节点数)。 对文档的新建、索引和删除请求都是写操作,必须在主分片上面完成之后才能被复制到相关的副本分片。
数据写入
ES 为了提高写入的能力这个过程是并发写的,同时为了解决并发写的过程中数据冲突的问题,ES 通过**乐观锁的方式控制**,每个文档都有一个 _version (版本)号,当文档被修改时版本号递增,一旦**所有的副本分片都报告写成功才会向协调节点报告成功**,协调节点向客户端报告成功。
当版本号冲突的时候,ES会提示冲突并抛出异常,并进行重试。
映射(Mapping)
映射是用于定义 ES 对索引中字段的存储类型、分词方式和是否存储等信息,就像数据库中的 Schema ,描述了文档可能具有的字段或属性、每个字段的数据类型。 对于字段类型可以不指定然后动态对字段类型猜测,也可以在创建索引时具体指定字段的类型。

- Text:用于索引全文值的字段,这些字段是被分词的。
- Keyword:用于索引结构化内容的字段,它们通常用于过滤,排序,和聚合。Keyword 字段只能按其确切值进行搜索。
文件存储
每个index(索引)都包含若干个Shard(分片),每个分片底层又是一个个Segment文件(段),每次数据的读写底层就是与一个个段文件的交互,因此ES调优常用的一块就是对段文件的调优,即对每个分片中段文件数据、大小控制,段合并(Merge)等。
数据存储文件:文件后缀:.fdx, .fdt,
- 索引文件为.fdx,索引文件记录了快速定位文档数据的索引信息,数据文件记录了所有文档id的具体内容。
- 数据文件为.fdt,数据存储文件功能为根据自动的文档id,得到文档的内容,搜索引擎的术语习惯称之为正排数据,即doc_id -> content,es的_source数据就存在这。
倒排索引文件:.tip,.tim
es倒排索引信息,分词后的结果?
倒排索引中term与docId的关联关系获取到原始数据
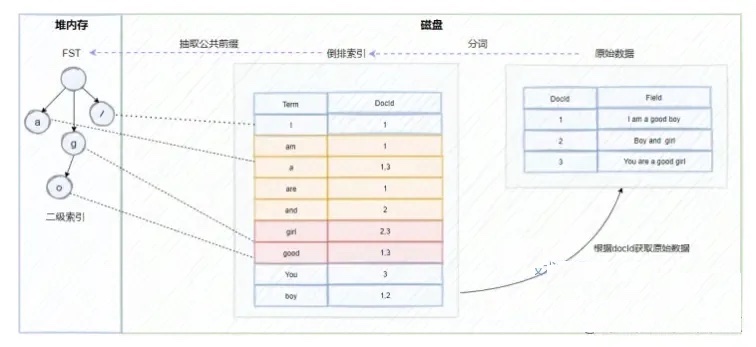
- 倒排索引对应的倒排表文件是存储在硬盘上的。如果每次查询都直接去磁盘中读取倒排索引数据,在通过获取的docId再去查询原始数据的话,肯定会造成多次的磁盘IO和效率问题,Lucene实际是使用了FST(Finite State Transducer)有限状态传感器来实现二级索引的设计,它其实就是一种有限状态机。
- FST是存储在堆内存中的,而且是常驻内存,大概占用50%-70%的堆内存,因此这里也是我们在生产中可以进行堆内存优化的地方。
索引过程